Throughout this whole semester, we have learned quite a few tools to assist us analyzing text in the “distant reading” way. Recently, we have learned a way to let machines read our corpus for us and further understand the context for us using some sort of algorithms on a macro level. Based on machines’ understanding, they are able to show the stylometry of our corpus. Stylometry allows me to consider at a comparative and macro level how different cultures and origins are related in terms of cooking.
Lexos
In order to analyze my corpus on a macro-level, I worked with a platform called Lexos. Lexos is a very intelligent machine for reading corpus and understanding them. It has several features that enables me to establish relationship between cultures. When I used Lexos, I first scrubbed my corpus using a list of stopword provided by Jigsaw (I also expanded the stopword list based on my corpus). After cleaning up my corpus, I tried multiCloud to get a nice visualization of my corpus like in Voyant:

These word clouds show nothing more than the key terms within each corpora. Nevertheless, I was looking for something more specific that can show if there is some kind of relationship between different cookbooks. Then I continued using another tool to create a dendrogram that Dr. James O’Sullivan had talked about last Monday. Here is the result I obtained:
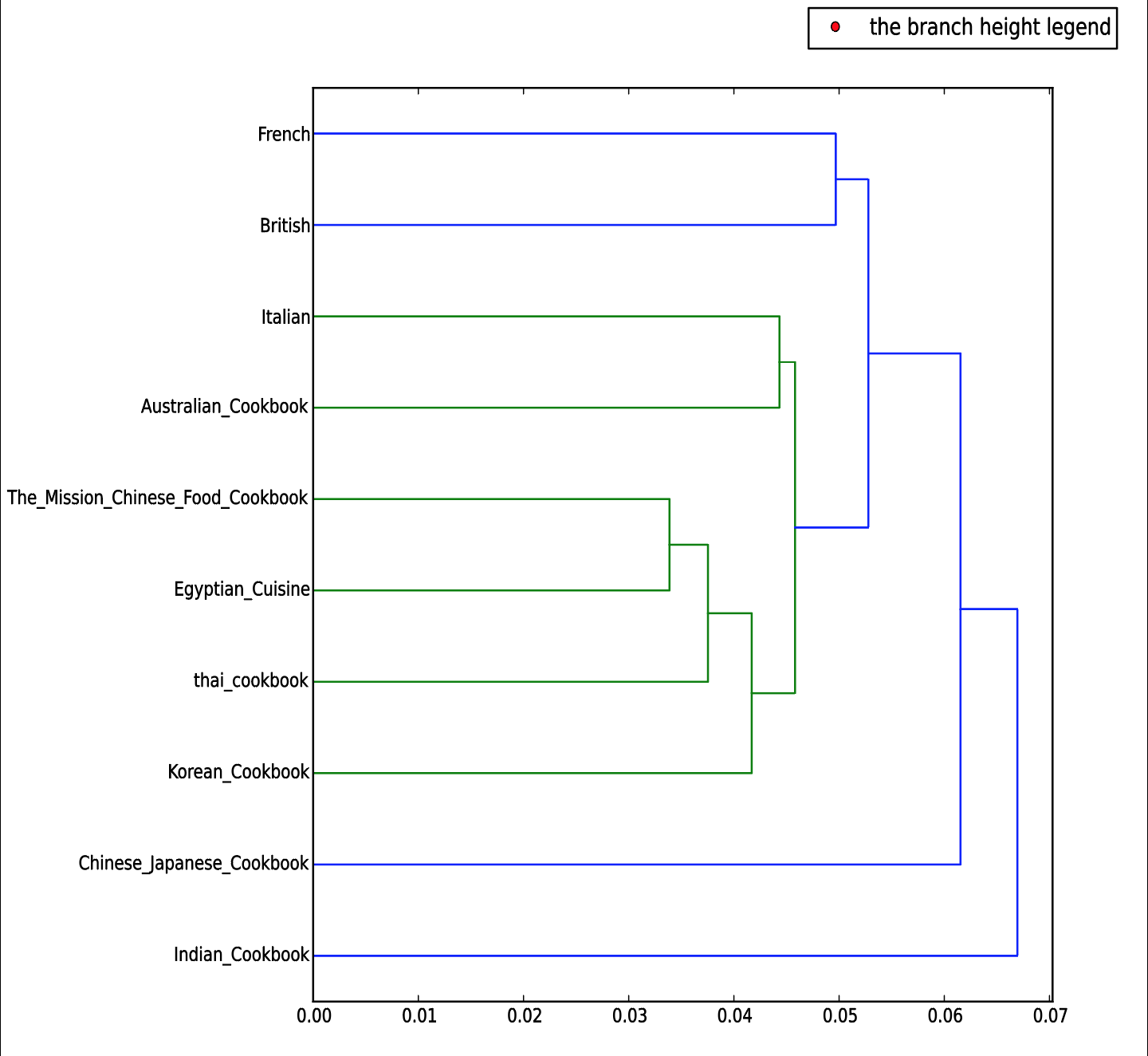
From the dendrogram, I found out that Chinese, Egyptian, Thai, and Korean Cookbooks share a lot of similarities. This result is not surprising since these cultures all locate geographically close to each other. It is quite interesting to find out that Italian cookbook and Australian cookbook are similar. I was expecting to see British cookbook share more similarities with Australian cookbook since Australian used to be a colony of Britain. Having this question in mind, I used another tool provided by Lexos to compare corpus. Here is the result I obtained:
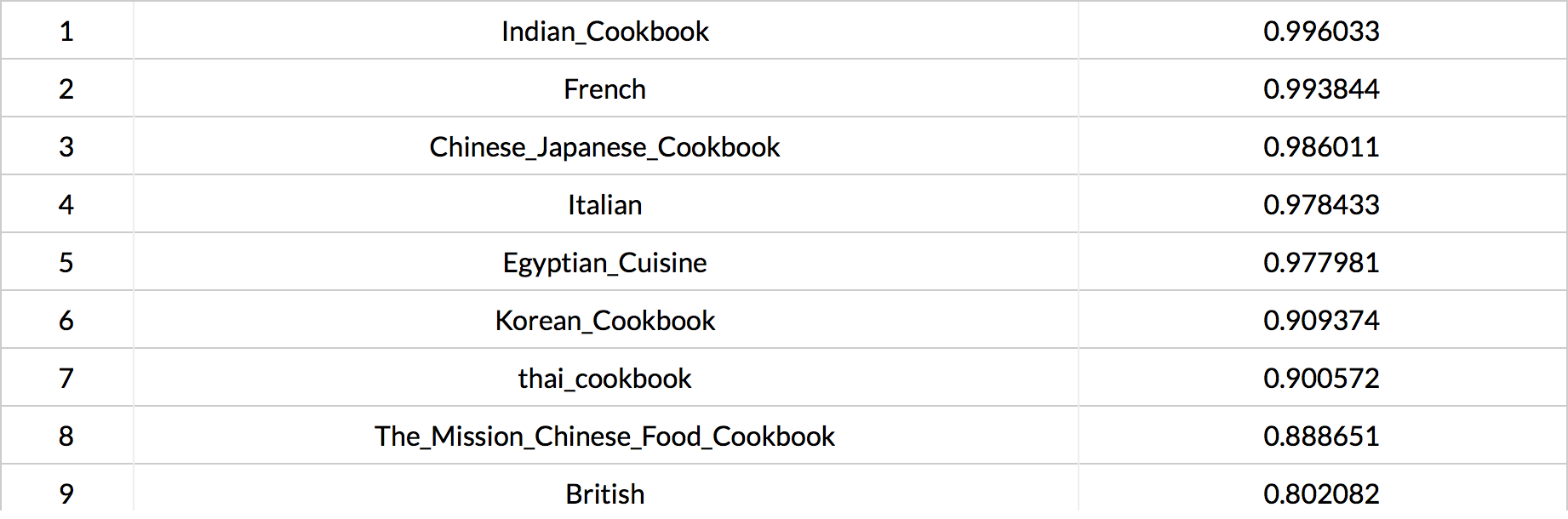
The figure above is the similarity rankings among all the cookbooks in my corpus. The higher the value, the closer the comparison document’s vector is to that document’s vector as opposed to the other documents’ vectors. This result really shocked me (without exaggerating). I was really expecting to see many similarities between Britain and Australia regarding cooking. It seems like the colonial effects are gradually fading away as time is flowing. However, Australian cookbook is very similar to Indian cookbook. In fact, Australia and India both used to be British colonies. Therefore, these results suggest that the colonial effects perhaps still exist in both cultures; Britain may happen to be the country that has evolved or improved its recipes.
TEI and XML
Finally, I also learned another way of analyzing my corpus on a micro-level. I can use XML to markup some important entities within the text of my corpus. I actually have some experience with marking-up desired entities within a large-scale corpus. I used Python scripts to extract personal information (name, age, occupation, father’s name, mother’s name, children’s names and grandfather’s name) from thousands of Chinese biographies in XML format. After extracting the text I was interested in, I attached entity tags wrapping around the part of text. Here is a piece of text from these Chinese biographies:
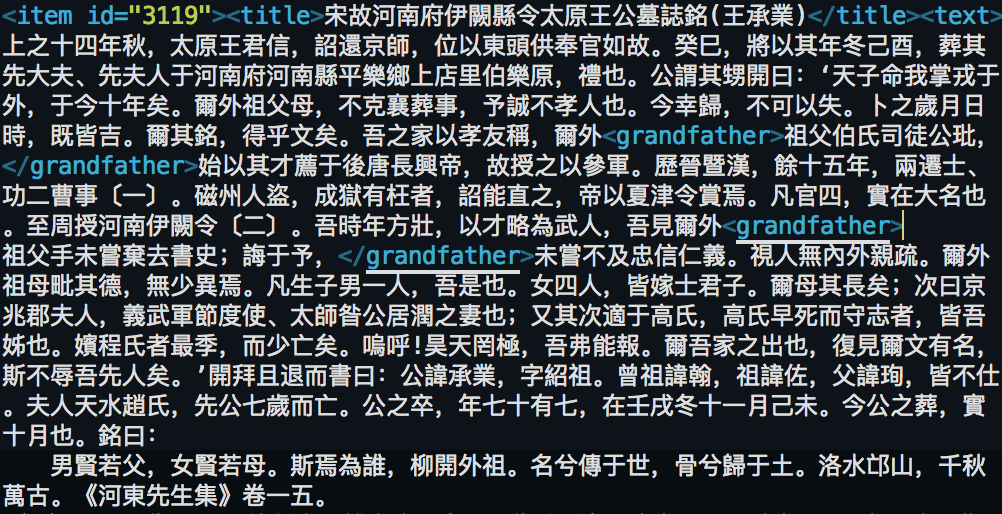
As you can see, there are some parts of text are wrapped by a <grandfather> tag; this means that specific part of text describes this person’s grandfather. Because of these tags, it becomes so much easier for me to let machine catch small fraction of text for me to analyze instead of reading a humongous text file. My past experience really excites me marking-up my cookbook corpus. I believe marking-up cookbooks will help my textual analysis technique to reach a whole new level. I have marked up all the protein and vegetables in my corpus. Here is one example:

For now, the generated HTML file is not showing anything special based on different tags. Yet I will tweak the CSS in order to make different kind of ingredients to stand out. In addition, I’m quite confident with the results I will get using text markup.