For my corpus I have chosen poems. I collected texts from four authors, I include Russian, English and Latin translation of the texts. In total I’m working with nine texts, it should give the representative sample. The range of my texts starts with Ancient Greece and Horace, then the Russian Empire in the XVIII-th century with Lomonosov, after the Russian Empire in the XIX-th century with Pushkin and it ends with the Soviet Union and Vladimir Vysotskiy.
They are very small 1-3 KB.
There a lot of poems with the idea when poet is building monument in his honor to make his work immortal. This tradition begun with Horace and I took Latin, Russian and English translation of his Monument. Since I’m working with Russian literature I decided to start with Lomonosov who arise this topic in Russian poetry in the XVIII-th century. The next poem is by Pushkin and with Pushkin Russian language changes a lot, he is the father of the Russian poetry and he reformed the language, the style a lot. Even thought it’s one century difference the language and writing style is totally different and I’ wondering if the program can these differences and show it to us. The last but not the least is the song by Vysotskiy where he’s building a monument for his work. Vysotskiy represents another style, we call it bard song. Also he lived in the XX-th century during the Soviet Union time when the government changed the language to its modern state we speak now.
My research questions: to find out which words or phrases are repeated, are these repetitions synonyms or not and according to that how does the translation change the original text, its meaning, its atmosphere. Also it’s interesting to compare poetic metric systems because it’s different for every language and how the translators were solving these problems. The main result of this work should show how the idea of building the monument has changed through the centuries.
Cleaning.
I deleted all unnecessary signs that were disturbing for the program. Working with Voyant I found out that there is no Russian stop-list words. I start creating my own stop-list, and then I realized that the program was reading the same word but with capitalized and small letter as a two different words. I went back to my texts, changed to capital letters to a small ones and only after that I created a stop-list.
Voyant
The best thing about Voyant is that it reads Russian!
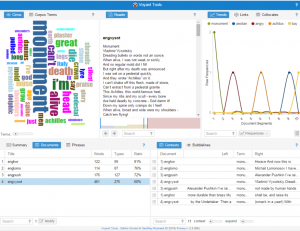
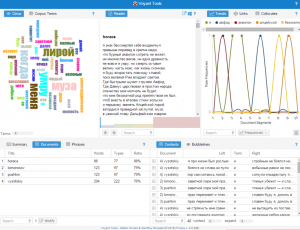
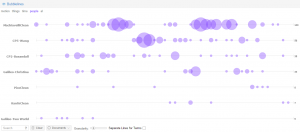
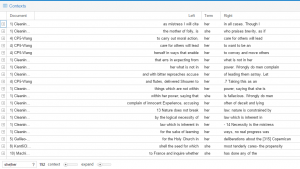
In English translation the main words are: monument, alive, death, muse. In Russian – die, muse, Alexander, lire. Word collocation is very useful, we see how words are surrounded by each other and it shows us the context where we can read the words. For this sort of work Voyant is amazing to use.
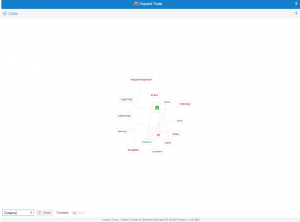
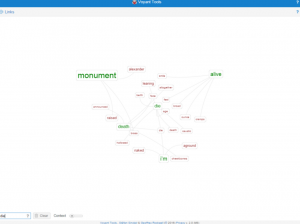
Here we can see that links in English give us more information than Russian one.
From Voyant we can make a conclusion that translations a different and they show us different sides of the poems.
Antconc
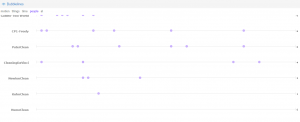
Antconc has also a lot of advantages, for instance, search with the key words, word collocation, cluster analysis, n-grams and etc. That shows us the position of the word in the text, which very useful because looking up at the position of the word we can make already the analysis without wasting time searching for that word in the text, the platform does it for you. Concordance and file view where you can search the word in the text (almost the same as Voyant). Doesn’t read Russian.
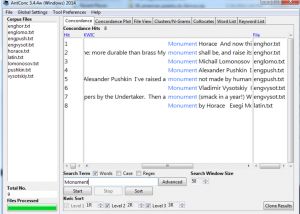
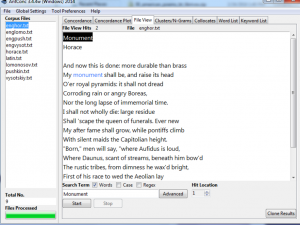
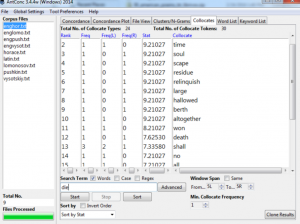
Collocate shows us which words your term is collocated by and it helps to understand what atmosphere author is creating, how he places the words. Then you can click on it and it will show the position of the word in the text.
Jigsaw
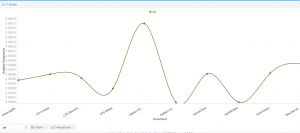
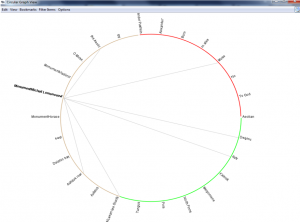
For my corpus more convenient was creating a word tree and circular graph to see the word dependence.
As you can see here the word “monument” actually is not that much mentioned in the text, which is surprising.
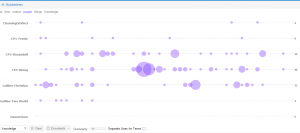
Poemage
The best tool for analyzing poems is Poemage. However it doesn’t like Russian too.
I divided poems into three groups: Horace and Lomonosov, Pushkin, Vysotskiy.
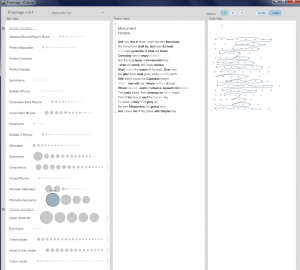
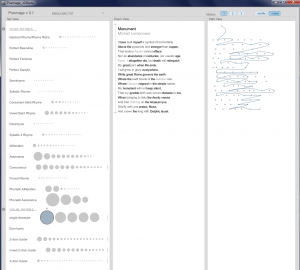
Here we have high style text, author talks with muses, his lire, very poetic and abstract.
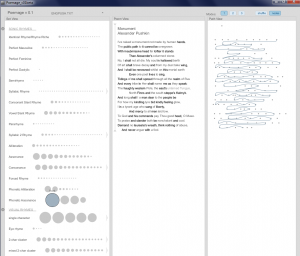
Pushkin changes the style (4foot yambic) and makes it more about himself: his work raised higher than Alexander’s columned stone, he is more important than the czar, he is writing about freedom, about peasants…his poems are his monument.
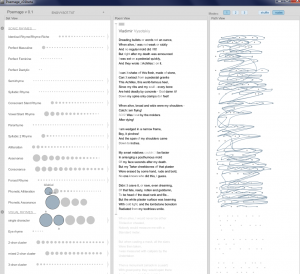
Vysotskiy changes the idea totally, he is still talking about life and death, but his poem is more sharp, rhythmic and politically oriented.
I enjoyed working with Poemage, for my future work I am planning to modify my corpus so I can more results with next tools we are going to work with.

 I was able to get the books from Project Gutenberg and one from Professor Faull; however, I acquired the supplementary readings in PDF form through my HUMN 150 instructor, Professor Shields.
I was able to get the books from Project Gutenberg and one from Professor Faull; however, I acquired the supplementary readings in PDF form through my HUMN 150 instructor, Professor Shields.

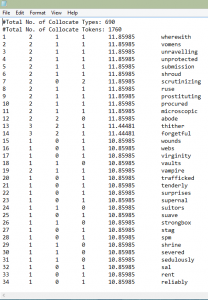 There were many other terms, some unique and a few repetitive, that were used to describe “she” and “her”.
There were many other terms, some unique and a few repetitive, that were used to describe “she” and “her”.