After a long period of deep pensive contemplation, I have emerged from my thoughts with a new found perspective on not only the digital marking of texts, but digital text reading as a discipline. The prompt for this blog asked “How has the process of stylometry and marking up affected your understanding of the corpus?”, and I would like to interpret this as my understanding of “the” corpus, not “my” corpus.
Regarding this, Pierazzo wrote “what we choose to represent and what we do not depends either on the particular vision that we have of a particular manuscript”. This brings up a brilliant point relative to all the work we are doing. Everything we do in this field is highly subjective. We choose the parameters, we choose the document, we choose the outcome. Much like the field of statistics, we set out to find proof to validate answers to questions. We propose research questions in order to give motivation and a frame to work in, but the honest truth is that in order to propose that research question, one must know about the works in question, and therefor must have biases. I would argue that 99% of the time research questions are proposed, researchers already have an answer in their mind, and this can shade their processes.
Pierazzo also wrote about the documentary digital editions of texts in her article, for example, stating they functioned “as the recording of as many features of the original document as are considered meaningful by the editors, displayed in all the ways the editors consider useful for the readers”. This is blatantly subjective, but not to a fault. It is just a fact, that the digital model of texts does not exist to escape subjectivity but the digital model exists to simplify analyses; “a model must be simpler than the object it models, otherwise it will be unusable for any practical purpose”
This is not meant to be a sentencing that all digital humanists will never be able to escape the binding of subjectivity, but instead, and I think Pierazzo would agree, is meant to be a simple reminder that we must keep in our mind when both reading analyses and analyzing ourselves. Each researchers individuality is what allows us to take on so many perspectives and attempt to understand them.
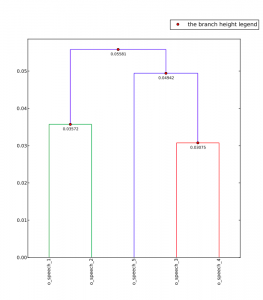
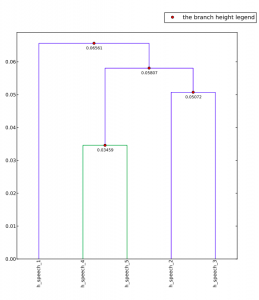
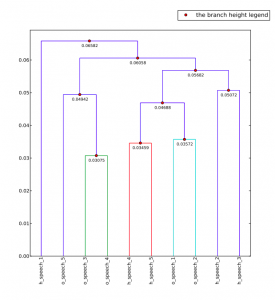
Keeping all this in mind, how has these processes affected my understanding of the corpus? Primarily, everything, including the corpus, is subject to biases. In order to illustrate this, I have a dendrogram of a particular section of Lord of the Rings. This section is separated into different sub-sections, once by the original creator of this digital text, and then a I combined all of these and had lexis, cut out sections using its own system. These were the results, 
The higher links are unimportant, but instead focus upon the fact that all of the sub-sections created by lexis are clustered, and all of the sub-sections that came distributed this way are clustered. Keep in mind that all of these are the same sections of text. This is simply proof that the corpus is an extremely subjective part of the research, just as much as the outcomes.
Next I went to go put this to work myself. I worked within the sections Tom Bombadil, in Lord of the Rings, and marked up nature related terms in his speech. 
I then wanted to compare the density of these references to those in his songs, but this is when I reached my large realization with digital mark up in oxygen; what is the end game? How would I complete my analysis? I think that oxygen needs to embed a way to analyze your marked up work into the actual program.
Drawing full circle now, I think that my work with oxygen and lexos have taught me an important thing that Professor Jakacki stressed during her presentation. Because one can mold the corpus in anyway possible, there is no end to the possible analyses one could do. It is important to keep the research question in perspective, and ask, when is enough, enough.