What if your computer could read your emotions?
The question above has been proposed for many years; however, recently, there has been more attention focused on sentiment and machine analysis. Upon hearing this question, some people enter a state of panic and distress. They assume their computer knows more than they do, thus taking control from human to mechanical hands. Nevertheless, I believe that machines “attempt” to read emotion, but emotion is much more complex than a machine, and even a human, could define.
Emotionless Machines
 According to Stephen Ramsey, “In an age when the computer itself has gone from being a cold arbiter of numerical facts to being a platform for social networking and self-expression,” it is important to understand the programs as a method to facilitate self-expression and networking (Ramsey 81). The programs used online do not create sentiment for you, as the writer, you must create emotion using your language. But can they recognize emotion?
According to Stephen Ramsey, “In an age when the computer itself has gone from being a cold arbiter of numerical facts to being a platform for social networking and self-expression,” it is important to understand the programs as a method to facilitate self-expression and networking (Ramsey 81). The programs used online do not create sentiment for you, as the writer, you must create emotion using your language. But can they recognize emotion?
For example, text messenger or email allows you to talk to someone without having a face to face or ear to phone conversation. You can type what your are feeling and send it to that person. However, how can the person receiving your message understand the tone or inflection of your voice from only text? It is up to the receiver to interpret your message. This is one example of Sentiment Analysis within the Digital Humanities. You can allow the computer to determine systematically the sentiment of the text, but it is up to the researcher to know the material beforehand and make solid conclusions based on both close and distant reading.
Text and email messages adopted emojis – “any of various small images, symbols, or icons used in text fields in  electronic communication (as in text messages, e-mail, and social media) to express the emotional attitude of the writer…”(Merriam-Webster Dictionary). These allow the receiver of a text to understand the sender’s connotation of the message by the expressions of the emoticons/emojis.
electronic communication (as in text messages, e-mail, and social media) to express the emotional attitude of the writer…”(Merriam-Webster Dictionary). These allow the receiver of a text to understand the sender’s connotation of the message by the expressions of the emoticons/emojis.
Is it possible for computers/machines to read emotion?
There are algorithms and platforms that can help a computer read emotion. The algorithms are “trained” by experimentation. One way an algorithm can identify the sentiment of a document or sentence is through a vocabulary. The computer selects the most frequent words from the document or sentence and categorizes them by adjectives, verbs, and negation. The computer is using context clues to locate the emotion. Another way in which an algorithm can identify sentiment is through applying machine learning (ML) techniques. It may treat it as a classification problem, compile the data and set up features to recognize sentiment. Thus, it is possible for machines to read sentiment systematically, although, the question lies with – how well can machines read emotion?
Within the Digital Humanities, we look to step back from the close reading of a text and observe it from a distance or “in another light.” From this we are able to draw differential conclusions. Similarly, the data found with sentiment analysis needs a human to interpret and categorize it. As Ramsey states, “Such numbers are seldom meaningful without context, but they invite us into contexts that are possible only with digital tools” (Ramsey 75). Also, it is important to remember that algorithms are derived from humans.
Topic Modeling
Topic Modeling is a way to strip sentences into individual words. It is possible to discern the semantic meanings of individual words depending on context. The machine chops your text into different parts. The machine is looking for a specific pattern. It looks for the co-occurrence of words within the documents and can compare them to a set of different documents.
When I went through and highlighted my own version of Lincoln’s Gettysburg Address, I realized that my own experiences, either influenced by culture, religion, education, etc., determined how I decided if a word was related to governance (in blue) or war (in red). Likewise, after Ramsey’s students realized their mistakes in categorizing the books of word density, he stated, “They have arrayed the objects of their intellectual life in categories that correspond, among other things, to the cultural penumbras in which texts are disseminated and taught” (Ramsey 73). The manner in which a teacher or professor discusses a book with his/her students can have ramifications with the students’ perceptions of the book.

The topic modeling system has its own experience through a set of documents. Using the program, the bigger the corpus the better it will be. The program will have more reliable information to determine the patterns of the words. Small sample sizes are not ideal, the program will not accurately be able to locate any patterns.
There are also problems with topic modeling. The program can believe it is finding patterns where there are no patterns to be found. You may attempt to extrapolate meaning from the data you get from topic modeling, when in fact you are unable to draw sound conclusions.

It is clear that my own list of topics resemble the keywords not only from my older word cloud, but also the keyness I tested for in Antconc. Each topic line, I had predicted the most significant text and was right every time. It is very interesting how the computer can generate texts similarity through “topics.” Topic Modeling helped me understand just how close in relation some of my keywords throughout my texts are.
Jigsaw & AlchemyAPI
 I received some interesting sentiment analysis from Jigsaw. For example, Pico’s Oration on the Dignity of Man was the “happiest” of my documents. Jigsaw was correct with identifying key words and even more surprising with the summaries. Additionally, Kant was categorized as the “saddest/angriest” of my texts. I know from reading both of these texts that Pico has a “happier” tone than Kant. However, they are not necessarily “happy” texts. Thus, you have to look at the vocabulary that Jigsaw was using to determine the sentiment analysis.
I received some interesting sentiment analysis from Jigsaw. For example, Pico’s Oration on the Dignity of Man was the “happiest” of my documents. Jigsaw was correct with identifying key words and even more surprising with the summaries. Additionally, Kant was categorized as the “saddest/angriest” of my texts. I know from reading both of these texts that Pico has a “happier” tone than Kant. However, they are not necessarily “happy” texts. Thus, you have to look at the vocabulary that Jigsaw was using to determine the sentiment analysis.
Upon closer look in Pico’s book, he uses terms such as “kindness,” “peace,” “natural,” and “holy.” Where as Kant’s  reading has terms like “unworthy,” “tolerance,” and “haughty.” It is imperative that you have read the materials you are using for sentiment analysis, so that you can utilize differential techniques when analyzing the data.
reading has terms like “unworthy,” “tolerance,” and “haughty.” It is imperative that you have read the materials you are using for sentiment analysis, so that you can utilize differential techniques when analyzing the data.
 my recent searches include the terms: “he” “she” “her” and “him”. I was looking for gender bias in my readings. I created a cirrus or word cloud using the maximum of 500 words
my recent searches include the terms: “he” “she” “her” and “him”. I was looking for gender bias in my readings. I created a cirrus or word cloud using the maximum of 500 words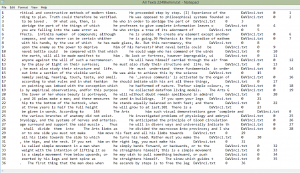
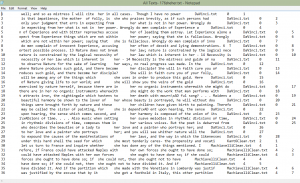
 This is a differential search from Voyant looking at some KWIC (keyword in context). I used both “he|him” and “she|her” to research the gender issue in depth. Usually, “he” is used to refer to a general population. The most interesting case is the use of “her” and “she”. The lexicon surrounding these terms is significantly ne
This is a differential search from Voyant looking at some KWIC (keyword in context). I used both “he|him” and “she|her” to research the gender issue in depth. Usually, “he” is used to refer to a general population. The most interesting case is the use of “her” and “she”. The lexicon surrounding these terms is significantly ne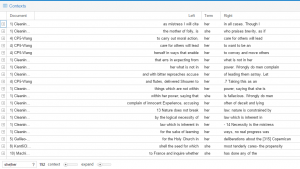 gative, such as “folly,”, “mistress,” and “bitter”. Also, “her” and “she” are frequently used to replace “nature” – purity, “law” and “deliberations” – mutable. When I refer to purity, I am speaking of the “sexually pure good girl”. When I use the word “mutable,” I am speaking of the way in which men view women as an object, and how men suppress women into the image they want to see.
gative, such as “folly,”, “mistress,” and “bitter”. Also, “her” and “she” are frequently used to replace “nature” – purity, “law” and “deliberations” – mutable. When I refer to purity, I am speaking of the “sexually pure good girl”. When I use the word “mutable,” I am speaking of the way in which men view women as an object, and how men suppress women into the image they want to see. 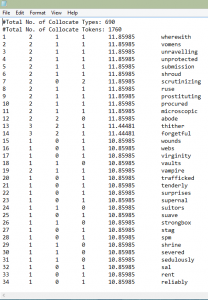 This screenshot is a collocation of “her|she”. This also enables me to see the negative lexicon surrounding the terms “her” and “she” throughout all my texts. There are terms like “submission,” “prostituting,” and “virginity.” This lexicon gives the impression that women are represented in my texts only as pure or “dirtied” and as objects. The greater part of this collocate has a plethora of words with negative connotations and denotations.
This screenshot is a collocation of “her|she”. This also enables me to see the negative lexicon surrounding the terms “her” and “she” throughout all my texts. There are terms like “submission,” “prostituting,” and “virginity.” This lexicon gives the impression that women are represented in my texts only as pure or “dirtied” and as objects. The greater part of this collocate has a plethora of words with negative connotations and denotations.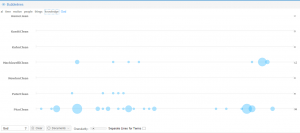
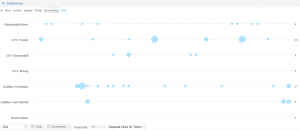
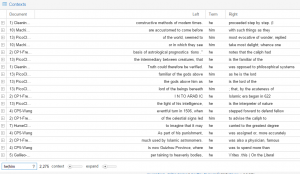
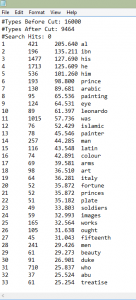 Antconc allows you to view the statistics behind the illustrations of Voyant. It is easy to see the collocations of a word, like “God”. Moreover, Antconc analyzes the frequency of a word (hits) and the terms used around that word (collocates), allowing you to click on a term and see its context in each reading. Antconc also allows you to have a reference corpus. A reference corpus allows you to see the keyness of a certain group of texts with regards to another corpus. For example, I referenced my Enlightenment texts to my Renaissance texts to see the keyness of the Renaissance texts. There were obvious words like “prince” and “painter” instead of words that belong to the Enlightenment like “time” and “motion.”
Antconc allows you to view the statistics behind the illustrations of Voyant. It is easy to see the collocations of a word, like “God”. Moreover, Antconc analyzes the frequency of a word (hits) and the terms used around that word (collocates), allowing you to click on a term and see its context in each reading. Antconc also allows you to have a reference corpus. A reference corpus allows you to see the keyness of a certain group of texts with regards to another corpus. For example, I referenced my Enlightenment texts to my Renaissance texts to see the keyness of the Renaissance texts. There were obvious words like “prince” and “painter” instead of words that belong to the Enlightenment like “time” and “motion.”