http://finalproject.blogs.bucknell.edu/
Categories
http://finalproject.blogs.bucknell.edu/

Machine Reading
As Elena Pierazzo states in her article, A Rationale of Digital Documentary Editions, “The process of selection is inevitably an interpretative act: what we choose to represent and what we do not depends either on the particular vision that we have of a particular manuscript or on practical constraints” (Pierazzo 3). Pierazzo’s view of on the process of marking up texts is similar to our first step within the process of a Distant Reading project – asking which general question you would like to research.
In terms of the Digital Humanities, I believe that the term “Machine Reading” is often misleading. The title implies that only a machine is reading the text and there is no human interaction. However, this is completely untrue. As Pierazzo mentions the process of selecting what you want to mark up within a text is an “interpretative act”. Thus, a human must choose which information within the text is essential to the reader.
Stylometry
Using such platforms as Lexos and TEI – oXygen, I have learned a multitude of new ways to approach analyzing my corpora. Platforms within the field of stylometry can be used to conduct macro-level and/or micro-level research. It is important to recognize the ability to use both Lexos and oXygen in tandem. In other words, you can perform both a distant reading with Lexos and a close reading with oXygen. Therefore, you can do differential analyses, synthesizing the various statistics and interpretations from each platform.
Lexos
Lexos is a great platform that has a myriad of options to clean and investigate your corpora. I was able to upload all of my documents to Lexos with no problems. Then, I had the opportunity to “scrub” my documents of stop words or any special characters. Fortunately, I had the stop word list from Jigsaw that I uploaded straight to Lexos. Then, I was able to visualize and analyze the data of my corpora. Under the visualize tab, there is WordCloud, MultiCloud, RollingWindow Graph, and BubbleViz. Some of the options are similar to other web sites, like Wordle. However, under the analyze tab, there is Statistics, Clustering – Hierarchical and K-means, Topword, etc. The most impressive and useful means to analyze my corpus was through the dendrogram and the zeta-test. Additionally, Lexos can cut and segment your texts into smaller documents by characters, words, or lines. This feature is helpful when using some DH platforms, like Jigsaw, that work better with smaller documents.
Investigating in Lexos
When skyping in with Dr. James O’Sullivan, I was able to learn of countless hermeneutical approaches using the features of Lexos and multi-faceted digital platforms. Stylometrics can produce, as Dr. O’Sullivan stated, “statistically significant” information, pending that the researcher is well-acquainted with his or her texts. Stylometrics supports critical interpretations and close readings. For example, Dr. O’Sullivan showed us the author attribution project used to detect J.K. Rowling’s anonymous books. The digital humanists used dendrograms, which measure texts in terms of similarities in vocabulary, to prove that a text must have been written by a certain author due to the overwhelming statistical evidence.
In Lexos, I made many dendrograms that displayed particular peculiarities in my corpora.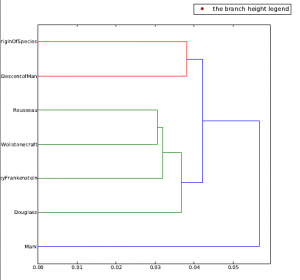
Both dendrograms display texts that I have read in HUMN 150 that are considered post-Enlightenment period. Specifically these dendrograms interest me because there is much similarity in the vocabulary throughout all the post-Enlightenment texts, except Marx, Kant, and Kleist. For example, when we read Frederick Douglass’s narrative, there are specific passages that contain lexicon reminiscent of Shelley’s Creature in Frankenstein. Moreover, Shelley and Douglass are shown to have similar vocabulary in both dendrograms. Even more so, Darwin’s On Origin of Species and The Descent of Man are paired together; this example supports the claim that stylometry produces “statistically significant” information.
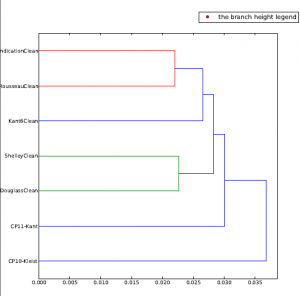
However, I was not completely satisfied with the results from my dendrogram. I wanted to create a zeta test which produced the distinctive words in each text based on the 100 MFW (most frequent words). 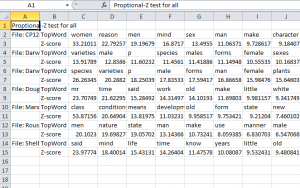
As you can see from this zeta test, the first line is Mary Wollstonecraft’s A Vindication of Women’s Rights shows the most unique/distinctive word to be “women” and for Jean-Jacques Rousseau’s Discourse on the Origin of Inequality shows the most unique/distinctive word to be “men.” Rousseau advocated for rights in general for all people during his Discourse. It is in Emile where he makes clear distinctions between men and women. However, the zeta test proves he is clearly still focusing in on men or generalizing the population with a masculine pronoun. (remember this is a translation) Also, these Antconc screenshots show collocations of the terms “women” and “men.” The first is of “women”; the second is “men.” If Rousseau is remaining fairly neutral throughout the Discourse, why does he use the term “men” more than “women”? 

TEI- oXygen Mark-up
I was able to practice micro-level stylometry through XML. TEI is a fascinating way to mark up your text. For example, I marked up a poem by John Keats, and was able to label certain lexical items depending how the author uses specific terms. Also, since you are the person marking up a text, you are picking out whether terms like “realms of gold” connotes “Heaven” or not. You need to understand the poem; it is much more than the machine.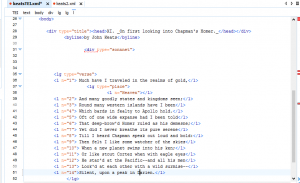
I have marked up Keat’s poem so that each verse could be shown separately for different annotations and meanings. The biggest problem with marking up texts in a semantic way is time constraints. As Pierazzo states, “Which features of the primary source are we to reproduce in order to be sure that we are following ‘best practice’?” (Pierazzo 4) It is evident that a person could tediously mark up a text for an extended amount of time; however, you must ask yourself, “What is the end result?” and “Have I answered, or helped in answering, my research question?
Pierazzo discusses the ways in which TEI helps to minimize the foreignness of the main text and the author. She states, “It is true that a diplomatic edition is not a surrogate for the manuscript when a facsimile is also present, but it is rather a set of functions and activities to be derived from the manuscript which challenge the editorial work and force a more total engagement of the editor with the source document” (Pierazzo 10).
Final Thoughts
Stylometry on both a macro- and micro-level have given me a new perspective on my corpus. Through TEI, I can markup certain texts and find the semantic meanings of specific passages. It is a way to become more familiar with your texts. Also, the dendrograms and zeta tests fill holes in my research that answer questions like, “Compared to Marx and Rousseau who discusses private property straightforwardly?” It is imperative to have both macro- and micro- analysis to give a differential view of the research results.
Throughout this whole semester, we have learned quite a few tools to assist us analyzing text in the “distant reading” way. Recently, we have learned a way to let machines read our corpus for us and further understand the context for us using some sort of algorithms on a macro level. Based on machines’ understanding, they are able to show the stylometry of our corpus. Stylometry allows me to consider at a comparative and macro level how different cultures and origins are related in terms of cooking.
Lexos
In order to analyze my corpus on a macro-level, I worked with a platform called Lexos. Lexos is a very intelligent machine for reading corpus and understanding them. It has several features that enables me to establish relationship between cultures. When I used Lexos, I first scrubbed my corpus using a list of stopword provided by Jigsaw (I also expanded the stopword list based on my corpus). After cleaning up my corpus, I tried multiCloud to get a nice visualization of my corpus like in Voyant:

These word clouds show nothing more than the key terms within each corpora. Nevertheless, I was looking for something more specific that can show if there is some kind of relationship between different cookbooks. Then I continued using another tool to create a dendrogram that Dr. James O’Sullivan had talked about last Monday. Here is the result I obtained:
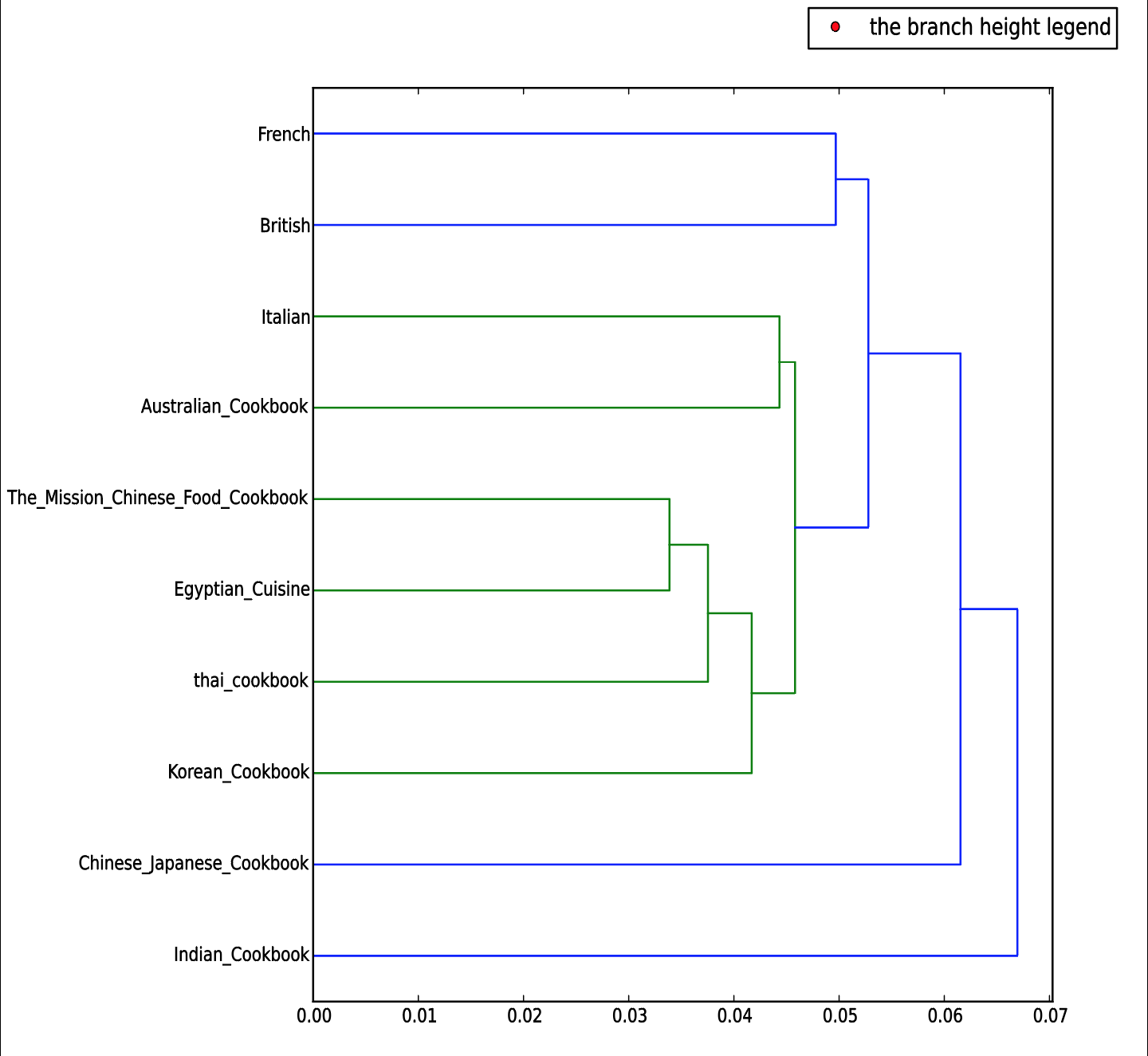
From the dendrogram, I found out that Chinese, Egyptian, Thai, and Korean Cookbooks share a lot of similarities. This result is not surprising since these cultures all locate geographically close to each other. It is quite interesting to find out that Italian cookbook and Australian cookbook are similar. I was expecting to see British cookbook share more similarities with Australian cookbook since Australian used to be a colony of Britain. Having this question in mind, I used another tool provided by Lexos to compare corpus. Here is the result I obtained:
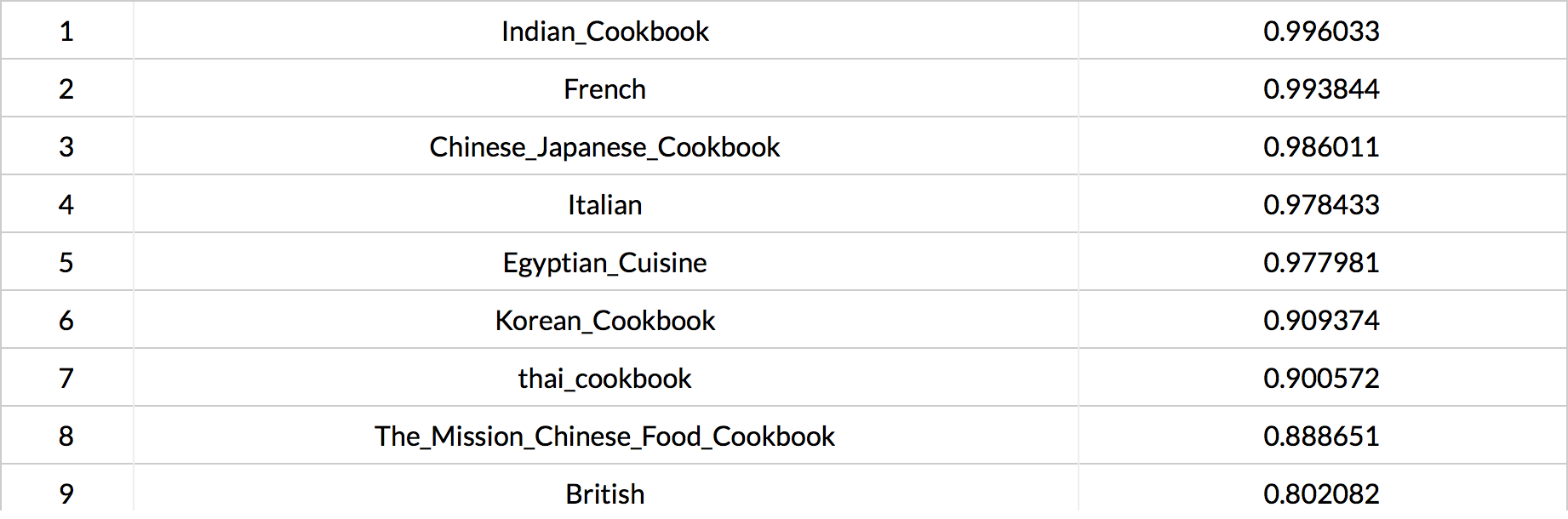
The figure above is the similarity rankings among all the cookbooks in my corpus. The higher the value, the closer the comparison document’s vector is to that document’s vector as opposed to the other documents’ vectors. This result really shocked me (without exaggerating). I was really expecting to see many similarities between Britain and Australia regarding cooking. It seems like the colonial effects are gradually fading away as time is flowing. However, Australian cookbook is very similar to Indian cookbook. In fact, Australia and India both used to be British colonies. Therefore, these results suggest that the colonial effects perhaps still exist in both cultures; Britain may happen to be the country that has evolved or improved its recipes.
TEI and XML
Finally, I also learned another way of analyzing my corpus on a micro-level. I can use XML to markup some important entities within the text of my corpus. I actually have some experience with marking-up desired entities within a large-scale corpus. I used Python scripts to extract personal information (name, age, occupation, father’s name, mother’s name, children’s names and grandfather’s name) from thousands of Chinese biographies in XML format. After extracting the text I was interested in, I attached entity tags wrapping around the part of text. Here is a piece of text from these Chinese biographies:
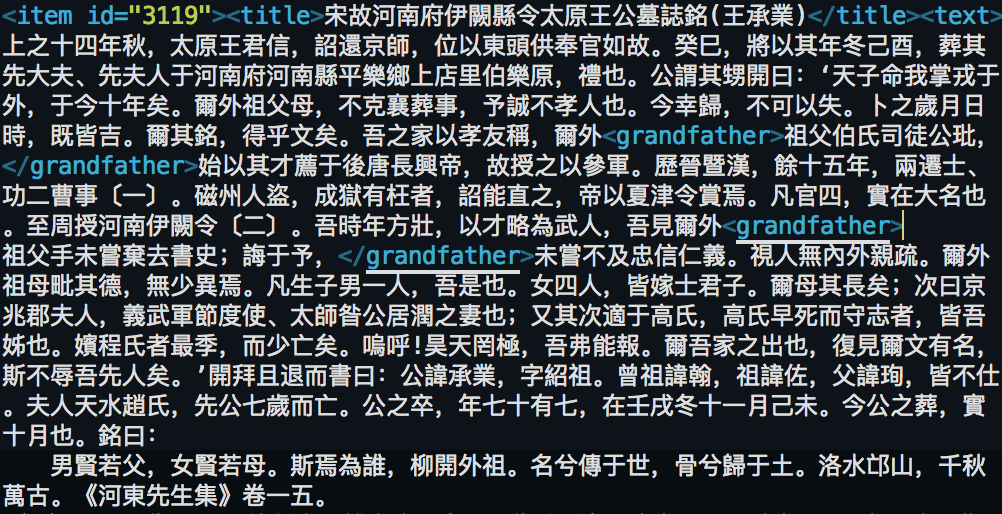
As you can see, there are some parts of text are wrapped by a <grandfather> tag; this means that specific part of text describes this person’s grandfather. Because of these tags, it becomes so much easier for me to let machine catch small fraction of text for me to analyze instead of reading a humongous text file. My past experience really excites me marking-up my cookbook corpus. I believe marking-up cookbooks will help my textual analysis technique to reach a whole new level. I have marked up all the protein and vegetables in my corpus. Here is one example:

For now, the generated HTML file is not showing anything special based on different tags. Yet I will tweak the CSS in order to make different kind of ingredients to stand out. In addition, I’m quite confident with the results I will get using text markup.