
General Reflection of Distant Reading
Digital Humanities is one of the most influential and meaningful fields to emerge in the past few years. Distant Reading allows for an extraction of the text off the page and illustrated through digital tools. This provides a clear overall reading that is not always evident through close reading, the traditional process of reading materials. Distant Reading is the ability to draw our attention from what traditional reading teaches and uncover the relation of patterns that emerge at a distance and close up.
At First Glance…
The process of Distant Reading begins by asking which general question you would like to research. Then, obtaining the documents needed for that research. Corpus creation could be a full time job. It is neither a project that has to be completed in any set interval of time, nor a project that must answer one distinct question. However, there must be an initial research question to begin an investigation. From that initial question and further analysis one can spawn new inquiries and explorations unbeknownst prior to the research. Indubitably, the best term to describe creating a corpus is the term “iterative”. It is important to realize the magnitude of one’s corpus, which might require narrowing the focus of the research.
My Corpus
I decided to create a corpus of all the readings from my Comparative Humanities class, HUMN 150. Throughout the duration of our class, HUMN 100, I intend to compare the 2015 syllabus with the first syllabus from 2000.
My research questions are:
- How did the HUMN 150 syllabus from 2000 change in terms of genres and authors (gender differences) to the syllabus in 2015?
- Also, the course was originally titled “Art, Nature, and Knowledge” and is now “Enlightenments,” what is the most accurate title, or what could be another title for the course?
 I was able to get the books from Project Gutenberg and one from Professor Faull; however, I acquired the supplementary readings in PDF form through my HUMN 150 instructor, Professor Shields.
I was able to get the books from Project Gutenberg and one from Professor Faull; however, I acquired the supplementary readings in PDF form through my HUMN 150 instructor, Professor Shields.
Cleaning & Parsing
I used OCR (Optical Character Recognition/Reader) on Adobe Acrobat Pro to convert the PDFs into text files (.txt), and I saved them in my google drive. My google drive is organized by “Renaissance&Enlightenment” texts, “Text Files from Gutenberg,” and “PDFs.” With these folders, I can keep track of which text files I am using. Also, I keep notes on my corpus construction that indicate what I keep and delete in each text file. Then, I cleaned each file by using Spellcheck.net, text fixer.com, and text cleansr.com. Using these websites, I removed line breaks, paragraph breaks, HTML script, and extra white spaces. Additionally, I manually cleaned each file correcting spelling and removing footnotes, some chapter titles, names of authors, and page numbers.
There were some odd mispellings through OCR, where a “.” would replace an “f”. Words would be randomly split apart, or there would be hyphens from a word split between lines. To manually fix this problem, I utilized the “Control Find” trick on my laptop to search for any letters that were directly after a period. (Crtl + F)
Modifying the Corpus
Previously above, I mentioned the “iterative” process of corpus creation. This becomes increasingly apparent when one realizes it is time to modify, update, and even begin an analysis of their corpora. Each platform helps to pick out mistakes as well; different views may show a KWIC (Keyword In Context) and the surrounding words might help find some misspellings.
For example: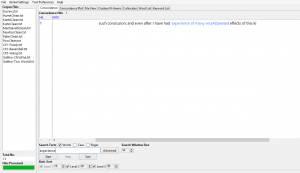
Upon seeing this, I went into my clean text file and noticed that the text was perfectly parsed at this spot. I even ran it through an html script checker. From this, I am able to find faults in the programs as well. Although, it is important to remember that nothing is perfect, and that is why we associate the term “iterative” with this research.
Gender Bias: Voyant, Antconc, & Jigsaw
Voyant was the first platform I used to start my analytical searches. The word cloud automatically defaults the amount of words in the box to 25. I decided to set the amount of words to the maximum, 500. 
This word cloud depicts the gender bias throughout the HUMN 150 texts. The prominent terms are both “he” and “him”. Also, the word cloud shows a myriad of other terms like “motion,” “people,” “science,” “man,”, and “mind” that demonstrate some of the key concepts of the European Renaissance to the beginnings of modernity in the 19th century.
Antconc showed the statistics that were not always present on Voyant and Jigsaw. For example, I did a collocation of both “he” and “him” compared to a collocation of “she” and “her”.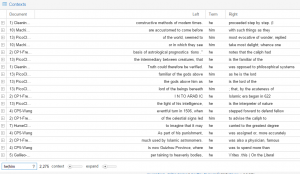
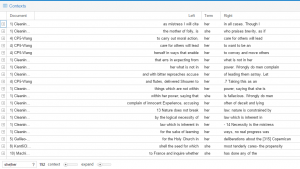
Overwhelmingly, it is mostly a negative lexicon surrounding the terms “she” and “her”. There are words like “mistress,” “bitter,” and “folly”. Taking this into consideration, I had to click on “she” or “her” depending on the sentence to see if the KWIC had a negative connotation or if it only seemed negative in that context through the collocation. Frequently, “she” and “her” were used to replace “nature” – purity, “law” and “deliberations” – mutable. The ‘sense’ of these words already is indicating weakness in women. In fact, this supports the claim that in most cases throughout my texts, women are viewed as an object rather than a human being. I question where the “humanist” thought is in this misogynistic view.
For “he” and “him”, the lexicon alluded to power. Some of the lexical items surrounding these terms were “God,” and “Lord.”
Antconc: Collocation of “she|her”
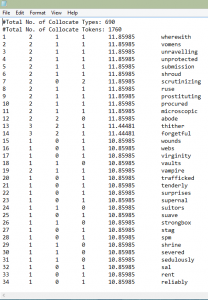 There were many other terms, some unique and a few repetitive, that were used to describe “she” and “her”.
There were many other terms, some unique and a few repetitive, that were used to describe “she” and “her”.
Some of these words include: “submission,” “scrutinizing,” “microscopic,” “prostituting,” and “virginity”.
This lexicon gives the impression that women are represented in my texts only as pure or “dirtied” objects. Throughout history, these words are commonly found when men are describing women. Consequently, all my texts for the Enlightenment and Renaissance era were written by males.
I have not used all of Jigsaw’s viewing platforms to their full potentials yet; however, I used the Jigsaw Tree view to allow me to illustrate a different collocation of the negative lexicon and the difference in the number of usage of “he” and “she”.


This clearly indicates the numerous times “he” was used compared to “she”. However, this is only representative of five of my texts. Moreover, the Jigsaw Tree of “he” only shows 17.273% which is 38/220 hits.
True Humanists
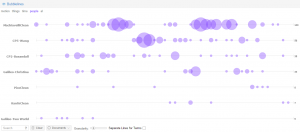
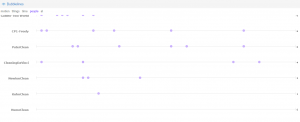
These are bubblelines I made on Voyant illustrating the frequency of “people” throughout the Renaissance and Enlightenments texts. It is clear that more than half of the writers seem to focus on the people in general. On the other hand, the other writers are specifically writing about a topic that is important to the world and people as a whole.
¿ “Art, Nature, and Knowledge” ?
The original title of the course “Art, Nature, and Knowledge” appears to have a consistent presence in all the texts. Using Voyant’s graphs and bubblelines, I was able to take a closer look.

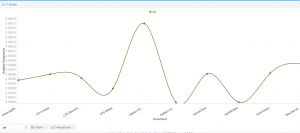
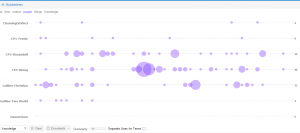

All of the terms are fairly consistent throughout the Renaissance and Enlightenment texts. Once I finish my corpus, I will be able to see if the title has validity or if I could come up with a better title for the course.
The FUTURE of My Corpus
Presenting my corpus to the class allowed me to focus on some of the key points I am trying to divulge in my analyses. Additionally, I was able to foster some new ideas with the help of my fellow classmates’ questions.
Now, I plan to search for both “women” and “men” with respect to the term “knowledge” in my corpus. I want to see if I can uncover any other biases. Also, I would like to add the translations of at least five major texts to see if the translations we are using in class are consistent with the original texts.
Finally, I really want to incorporate sentiment analysis into my research as well. I have theorized using Antconc to discover the negative lexicon in specific passages within my texts, thus being able to see the exact spots I could break the texts to fit Jigsaw to look for sentiment. Also, using Antconc to make an entity class is a brilliant idea.
I am eager to learn Mallet and further my knowledge in the Digital Humanities. Hopefully I will be able to add sentiment along the way and draw a plethora of intriguing conclusions towards the end of the semester.