My project url is http://www.eg.bucknell.edu/~yl015/index.html.
Categories
My project url is http://www.eg.bucknell.edu/~yl015/index.html.
Throughout this whole semester, we have learned quite a few tools to assist us analyzing text in the “distant reading” way. Recently, we have learned a way to let machines read our corpus for us and further understand the context for us using some sort of algorithms on a macro level. Based on machines’ understanding, they are able to show the stylometry of our corpus. Stylometry allows me to consider at a comparative and macro level how different cultures and origins are related in terms of cooking.
Lexos
In order to analyze my corpus on a macro-level, I worked with a platform called Lexos. Lexos is a very intelligent machine for reading corpus and understanding them. It has several features that enables me to establish relationship between cultures. When I used Lexos, I first scrubbed my corpus using a list of stopword provided by Jigsaw (I also expanded the stopword list based on my corpus). After cleaning up my corpus, I tried multiCloud to get a nice visualization of my corpus like in Voyant:

These word clouds show nothing more than the key terms within each corpora. Nevertheless, I was looking for something more specific that can show if there is some kind of relationship between different cookbooks. Then I continued using another tool to create a dendrogram that Dr. James O’Sullivan had talked about last Monday. Here is the result I obtained:
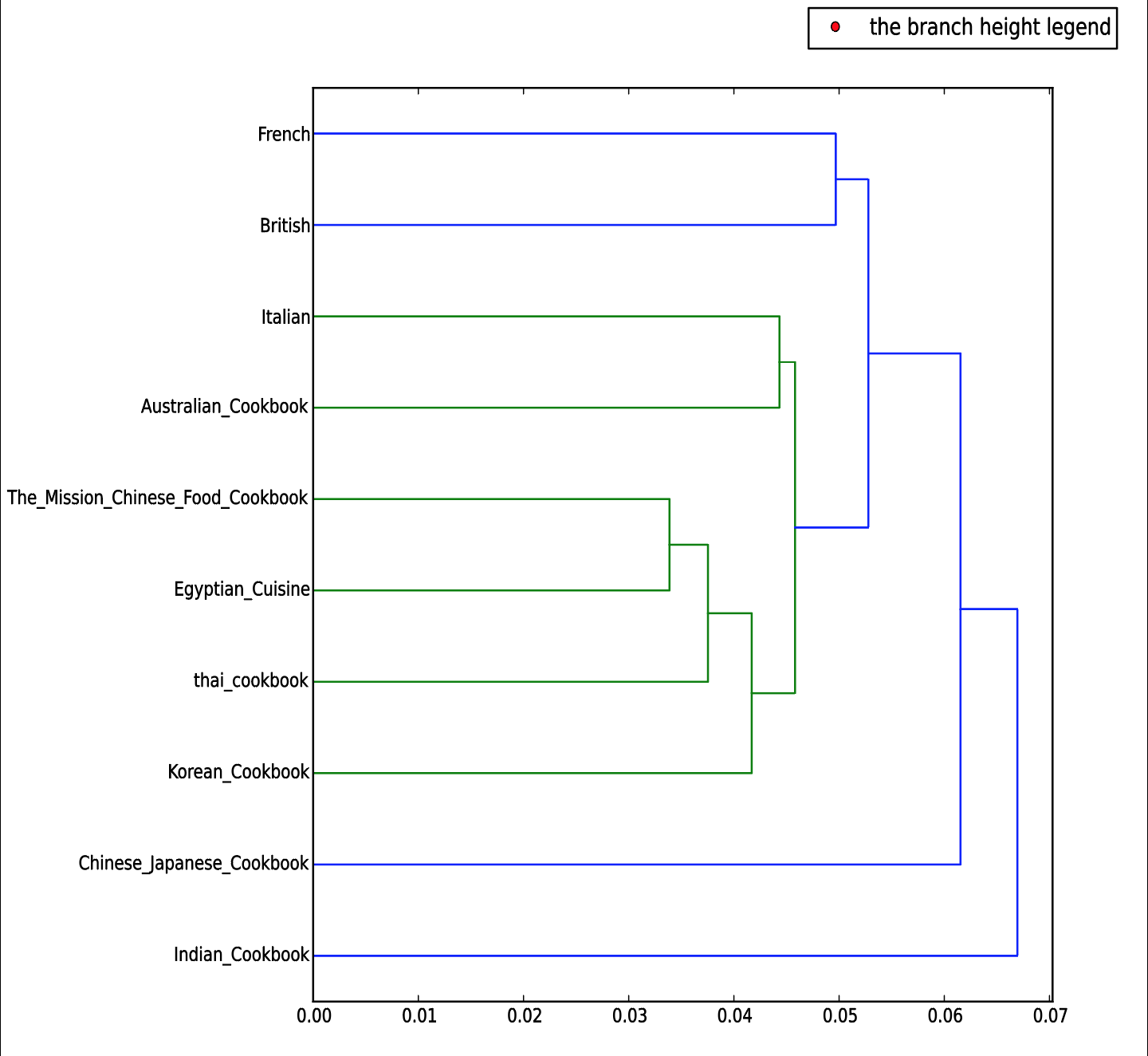
From the dendrogram, I found out that Chinese, Egyptian, Thai, and Korean Cookbooks share a lot of similarities. This result is not surprising since these cultures all locate geographically close to each other. It is quite interesting to find out that Italian cookbook and Australian cookbook are similar. I was expecting to see British cookbook share more similarities with Australian cookbook since Australian used to be a colony of Britain. Having this question in mind, I used another tool provided by Lexos to compare corpus. Here is the result I obtained:
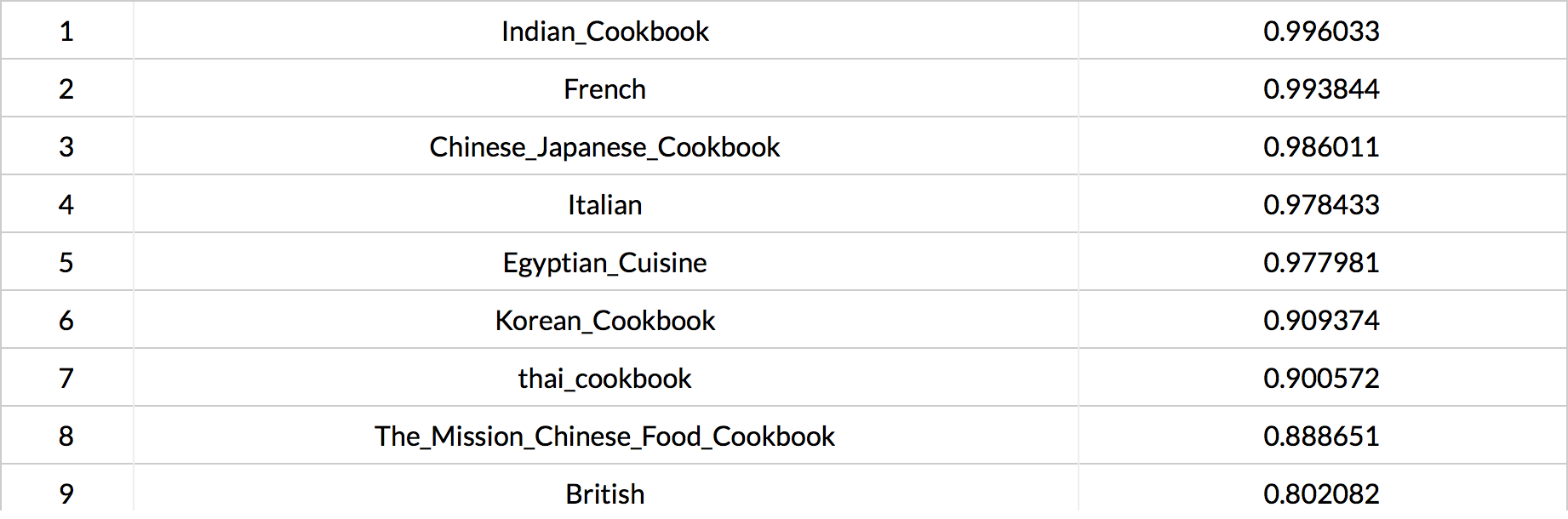
The figure above is the similarity rankings among all the cookbooks in my corpus. The higher the value, the closer the comparison document’s vector is to that document’s vector as opposed to the other documents’ vectors. This result really shocked me (without exaggerating). I was really expecting to see many similarities between Britain and Australia regarding cooking. It seems like the colonial effects are gradually fading away as time is flowing. However, Australian cookbook is very similar to Indian cookbook. In fact, Australia and India both used to be British colonies. Therefore, these results suggest that the colonial effects perhaps still exist in both cultures; Britain may happen to be the country that has evolved or improved its recipes.
TEI and XML
Finally, I also learned another way of analyzing my corpus on a micro-level. I can use XML to markup some important entities within the text of my corpus. I actually have some experience with marking-up desired entities within a large-scale corpus. I used Python scripts to extract personal information (name, age, occupation, father’s name, mother’s name, children’s names and grandfather’s name) from thousands of Chinese biographies in XML format. After extracting the text I was interested in, I attached entity tags wrapping around the part of text. Here is a piece of text from these Chinese biographies:
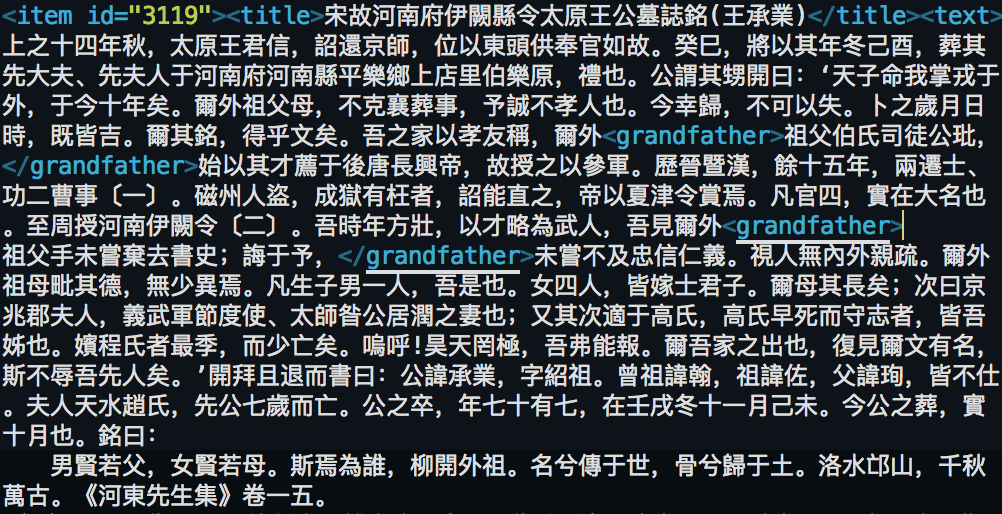
As you can see, there are some parts of text are wrapped by a <grandfather> tag; this means that specific part of text describes this person’s grandfather. Because of these tags, it becomes so much easier for me to let machine catch small fraction of text for me to analyze instead of reading a humongous text file. My past experience really excites me marking-up my cookbook corpus. I believe marking-up cookbooks will help my textual analysis technique to reach a whole new level. I have marked up all the protein and vegetables in my corpus. Here is one example:

For now, the generated HTML file is not showing anything special based on different tags. Yet I will tweak the CSS in order to make different kind of ingredients to stand out. In addition, I’m quite confident with the results I will get using text markup.
Artificial Intelligence has grown to be one of the most popular areas in Computer Science recently. Researchers have been contributing days and years on inventing and researching algorithms to make machines to learn all kinds of things. I have to say that researchers have made a lot of progress since AIs are blending into people’s daily life. Just two weeks ago, many peo![]() ple were following the greatest Go battle between human and machine. The machine that was involve was called AlphaGo. AlphaGo is a computer program developed by Google DeepMind in London to play the board game Go. It beat Lee Sedol in a five-game match. It was the fist time a computer Go program has beaten a 9-dan professional without handicaps. People were impressed and shocked by how smart a computer program was. It is scary to see machines are becoming more intelligent than human in some fields.
ple were following the greatest Go battle between human and machine. The machine that was involve was called AlphaGo. AlphaGo is a computer program developed by Google DeepMind in London to play the board game Go. It beat Lee Sedol in a five-game match. It was the fist time a computer Go program has beaten a 9-dan professional without handicaps. People were impressed and shocked by how smart a computer program was. It is scary to see machines are becoming more intelligent than human in some fields.
Although some machines have relatively high IQ, do they have high EQ as well? Can machines adopt some kinds of algorithms to read people’s emotions? Can machines really understand what people are talking about semantically? Over the last two weeks, I have been using Topic Modeling tool Mallet and Sentiment Analysis tool Alchemy API to analyze my corpus. I was looking forward to finding out how well can a machine understand my corpus.
I first used Mallet to generate a list of topics contained in the text. Here is the result from output_html:

For some reason, I was unable to navigate to specific chunks of text that generate these topics. Then I tried command-line Mallet to see if there’s any luck. The results I got:

Although the topics can be shown, I was still unable to navigate to the text. Looking at the topics generated by Mallet, I was not very satisfied with its understanding of my corpus. I would not consider these words as “topics” since they are not general. Also, I think these words are only key ingredients in all the cookbooks in my corpus.
Moving onto using machines to do sentiment analysis, I selected one recipe from the Chinese-Japanese Cookbook. I uploaded the selected recipe to Alchemy. Here is the result I obtained:

It is interesting to see that some ingredients in this recipe are considered to have positive and negative sentiment. For example, “cold water” indicates a negative sentiment. I think it is reasonable to say so. Cold water could indeed bring pain to people. However, according to contexts, cold water does not necessarily express a negative sentiment in a recipe.
I also made Alchemy to read this recipe’s emotions:

I was surprised to see a recipe can express these different emotions. I figured Alchemy does all the analysis based on certain keywords’ apparent meaning instead of their meanings in the context.
Nevertheless, I should not totally blame on machine not being able to understand me. Even people disagree with each other sometimes. Like the example we did in class, people had different opinions on what words should be considered related to “war” or “nation”. It is acceptable for machines to misunderstand us.
Ramsay said ” What is different about digital archives is the way in which text analytical procedures (including that most primitive of procedures: the keyword search) has the potential to draw unexpected paths through a documentary space that is distinguished by its overall incomprehensibility. ” in his article “patacomputing”. I think he’s trying to tell us not try to fully rely on machines to do textual analysis. However, treat machines as useful tool to assist us. Machines can sometimes discover connections within text that cannot be found by human.
Ramsay also claimed that “It is manifestly impossible to read everything, and it has always been so. ” Yet digital tools “are capable of presenting the bare, trivial truths of textuality in a way that allows connection with other narratives-in particular, those narratives that seek to install the text into a network of critical activity.” Therefore, tools like Alchemy and Mallet have big potentials that await me to discover.