According to T. Clement distant reading is “reading closely and at a distance, subjectively and objectively, with new methodologies … close attention to databases, data flows, and data architectures, including attention to the human element behind them”. But what is actually behind this term? The twenty first century brings us to a new “era” of text analysis, which allows us to use more tools and analyze the results “previously unnoticed”. Ted Underwood calls this method ” gateway drugs”, once you start exploring you want to try more tools… For instance, there is a program Hyper Pro (Voyant) which we can use to compare the word frequencies; Many Eyes shows you one way the text is different from the other; MONK is developing “data-mining and visualization applications that helps scholars to access to large-scale text collections” and Hoover was using PCA and Cluster analysis to find the frequencies of the one hundred most frequent words. Also, Hoover says that ” the computer’s greatest strength are in storing, counting, comparing, sorting and performing statistical analysis. This makes computer-assisted textual analysis especially appropriate and effective for investigating textual differences and similarities…”. T. Clement has the same position “these analytics and visualisations help us generate a new knowledge by facilitating new readings of the text and by affording a self-reflective stance for comparisons, a perspective from which we can begin to ask why we close readers have found some patterns and yet left others undiscovered”.
One of the analysis I find complicated is the computer-assisted textual analysis made by Hoover. There he was looking for the differences in poetic vocabulary among a group of twenty six male and female American poets between 1911 and 1943. There he says that there typical or “stereotypical” female markers as “mother, children, mirrors” and male are ” beer, lust”. But there were some exceptions too, as “first” for female and “song, dancing” for male markers.
We worked with very useful platform Wordle, where you can easily find out the most frequent words in the text but it also creates an image of that words and “writes” the most frequent once bigger than the rest of the words. You control which particular words you need, you can remove the words you do not need, for example, “all Russian words” and etc. You can use this program as introducing the most frequent words as topics of your analysis, then you can cluster analysis according to the same results.

However, still there is a negative side of these programs: how to distinguish the words you need from the rest homographs and different meanings of the same word…as for me, it is still hard. For example, last class we were comparing Google N-grams and Culturnomics.
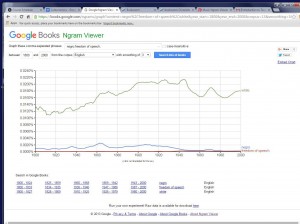
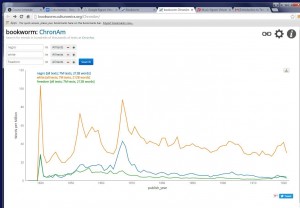
The search words were “white, negro, freedom of speech”. As you can see, Culturenomics gives us information only till 1920s, and “white” is more frequent than “negro, freedom of speech”. Why? “White” could be everything (color of skin, using it in art, in literature), it’s less specified. Also, the usage of the word “negro” is shown “less” as it supposed to be in this period of time, so we can say they give us more “official point of view”. But what is really nice in this website you can find old newspapers, magazines, etc. and read it online without going to the library or archives.
Google N-grams show you more “modern” period till 2000s. They show the same the word “white”, but differently the word “negro”. I would say on the n-gram it is closer to reality, if you look at the frequencies of using it from the 1860s till the mid 1980s you will find that at that time were the highest points of using it (which is closer to the history of the usage of the word). Also Google N-grams give you more choice of text, for example, with the word “white”:
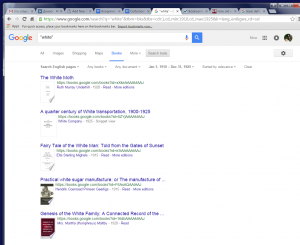
beginning with sugar manufacture and ending up with fairy tale.
There are many ways of representing the text, but the idea of “Many Eyes” (not only the program) should be always on the first place so we can “filter” the information that machine gives us, because machine can not find the concept, it gives us only numbers, statistics, frequencies and only we can solve the problems or find a new understanding of the text according to the results we got from the machine.
