For my corpus I have chosen poems. I collected texts from four authors, I include Russian, English and Latin translation of the texts. In total I’m working with nine texts, it should give the representative sample. The range of my texts starts with Ancient Greece and Horace, then the Russian Empire in the XVIII-th century with Lomonosov, after the Russian Empire in the XIX-th century with Pushkin and it ends with the Soviet Union and Vladimir Vysotsky.
There a lot of poems with the idea when poet is building monument in his honor to make his work immortal. This tradition begun with Horace and I took Latin, Russian and English translation of his Monument. Since I’m working with Russian literature I decided to start with Lomonosov who arise this topic in Russian poetry in the XVIII-th century. The next poem is by Pushkin and with Pushkin Russian language changes a lot, he is the father of the Russian poetry and he reformed the language, the style a lot. Even thought it’s one century difference the language and writing style is totally different and I’ wondering if the program can these differences and show it to us. The last but not the least is the song by Vysotsky where he’s building a monument for his work. Vysotsky represents another style, we call it bard song. Also he lived in the XX-th century during the Soviet Union time when the government changed the language to its modern state we speak now.
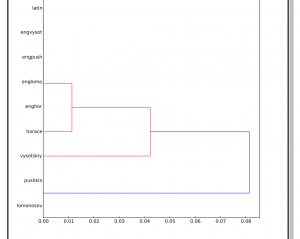
My final research question is based on the results of Lexos:
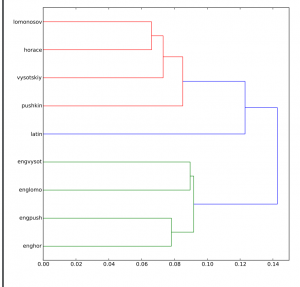
Here you can see Russian translation matching is logical: Lomonosov and Horace have close relation because Lomonosov was translating Horace. Vysotsky and Pushkin also match because they use modern Russian language. Unexpected results were 1. style of Vysotsky (who lived in USSR at 70s-80s) was also close to Lomosov (who lived in Russian Empire at XVIII century), which I can hardly believe and which I’m going to double check. My guess for now is that probably the program caught the MFW in those two poems as “Muse” and other old Greek names and words; 2. Pushkin (who lived in XIX century) was also close to Vysotsky style and that’s at least understandable because both poems were about building a monument to themselves through their works and that both poets were writing against the present system in the country. for me, that’s amazing that machine could see these details that I didn’t pay attention before. This reminded me skype-talk with Dr. O’Sullivan when we were talking about certain authors styles and how we can compare them. Of course, the most part the comparative analysis still will do the researcher not machine, using the advantages of close reading. The final question according to these results and my thoughts is why the machine shows the connection where it’s not supposed to be? Why the difference is only in English translation?
What to do to see the real differences? Need to combine close and distance reading methods, translation theory, metric system of both languages. My algorithm was this : Mark up texts in oXygen->Check Word collocation in Voyant->Use Poemage to see the rhymes.
oXygen.
You can get more sophisticated about how you want to look at your text in the browser – and why you want others to look at certain things, too. As Pierazzo mentions in her work that marking up the text is an “interactive act”, I would add to that it could be “a complete disaster” or “making love with your text”.
Using this tool we need to know which parts of text we want to focus on. Here we can come back to Pierazzo and what she thinks about that “Which features of the primary source are we to reproduce in order to be sure that we are following ‘best practice’?” Marking up the text is very convenient, you are deciding at how many topics you want o focus in your text, for instance, only names and places.Then you mark up all particular words that are related for names and places. But here is the trick: working with poems I can’t say that this is only “black or white”. Marking up the text is your own personal way of seeing it.
I used only several tags for my mark up (not the whole poem):
<placeName>
<persName>
<objectType>
<time>
<term type=”…”> (metaphor, synonym, allusion, etc.)
<note> (goes outside of poem structure but allows for editorial interpretation.)


(I’ll email you the rest of files).
The result in oXygen was unexpected: Russian translation of Horace has many parts of the speech that are different from the English translation that’s why here we have more names. Lomonosov in English poem keeps the places and names and at the same time he is adding new names (Aquilo,Rome, Muse) and phrase (My homeland will not keep silent), where in the Russian one is only the 5th line is different from Horace: instead of “not wholly die”(ves’) is “won’t all die” (vovse). Pushkin in English poem starts a new tradition with adding a new Russian not Greek/Roman place (Alexander’s column) and he also is adding nations, soul and God. No mentions about Russia in this translation. Vysotsky in English poem totally changes the topic and idea of the monument itself. Here
monument is stone on his grave, that people built for his death. He adds sounds, body parts, a coffin maker and curse words also, and gets rid of ancient names and places. In Russian poem Vysotsky is going far away from the tradition, no ancient names or places are mentioned. He brings up sounds, physical description, but no curse words…He also says “monument” not “pamyatnik”
as a symbol of his grave and people(government) wanted to get rid of him. But at the end of the song
he is becoming alive and laughing at all these people who “put him into grave”…
But why everything would be so different? The problem is in translation and marking up the text helped me to see it more in details. Russian texts have more “slavyanisms” etymologically Russian words that can be used for stylization purposes in Russian but the English translation can’t show it because in English it simply doesn’t exist. For instance Russian words for “head” – “golova” and “glava”. Both mean the same – “head” – but in Russian text the author can use one or another for stylization or to keep the rhyme. Here we’re dealing with, as Antoine Berman would say, deforming tendencies of the translation which is called “negative analytic”. Berman says: “The negative analytic is primarily concerned with ethnocentric, annexationist translations and hypertextual translations (pastiche, imitation, adaptation, free writing), where the play of deforming forces is freely exercised”. I think, in my corpora I have ennoblement type (the creation of elegant sentences), quantitative impoverishment (lexical loss, destruction of chains of signifiers). For example, Vysotsky’s poem, first two lines in Russian now mention of the “alive”, in English one it’s right in the second line.
Because of that the word collocation in Voyant is very different:
 (I’ll die, head, part, was, death, lyre, monument, Muse).
(I’ll die, head, part, was, death, lyre, monument, Muse).
 Looking at two word clouds we can say that the Russian one is pessimistic and using more word “death”, when in English one we can see more words related to “alive” and it’s more positive.
Looking at two word clouds we can say that the Russian one is pessimistic and using more word “death”, when in English one we can see more words related to “alive” and it’s more positive.
Analyzing poems we need to remember about metric system. English has and accentual verse and therefore beats and offbeats (stressed and unstressed syllables) take the place of the long and short syllables of classical systems. In most English verse, the metre can be considered as a sort of back beat, against which natural speech rhythms vary expressively. The most common characteristic feet of English verse are the iamb in two syllables and the anapest in three. Russian has accentual-syllabic verse which is an extension of accentual verse which fixes both the number of stresses and syllables within a line or stanza. Accentual-syllabic verse is highly regular and therefore easily scannable. Usually, either one metrical foot, or a specific pattern of metrical feet, is used throughout the entire poem; thus we can talk about a poem being in, for example,iambic pentameter… All these differences we can see in Poemage:
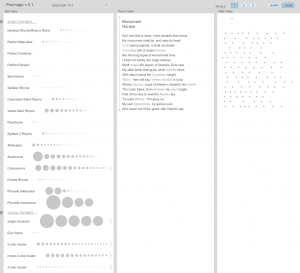
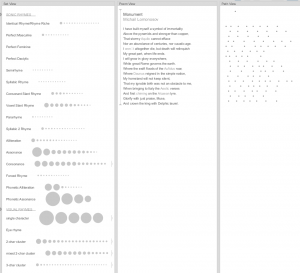


If we take a look on the schema of these four poems, we’ll see why Lexos “decided” to match in English translation Vysotsky and Lomonosov, Pushkin and Horace -> each group has almost the same assonance, alliteration, that’s why, I think, Lexos divided them in this two strange groups, because the words, used in each group were creating the same assonance, alliteration and etc. Basically, words in English translation doesn’t show all the richness of Russian language.
As Dr. Diane Jakacki was telling at class “Imagine you are an eagle, and from the height of your flight you see down in the prairie a little mouse” – this is a very good metaphor for the work that we’re doing at class this semester. I think, using digital humanities for the text analysis purposes is great and lets you to look at the text from the different point of view, “many eyes” technique. Just as Bathes “Death of the Author” we are now experiencing “death of the reader”. Although, working closely with tools I realized that reader is not dead, he’s very active, he “interacts” with machine and produces a new text that gives us many answers or leaves us with many questions.
References:
Berman, A. (1985b/2000) ‘La traduction comme epreuve de l’etranger’, Texte 4(1985): 67-81, translated by L. Venuti as ‘Translation and the trials of the foreign’, in L. Venuti (ed.) (2000),pp. 284-97.
Clement, T. Text Analysis, Data Mining and Visualisations in Literary Scholarship. Electronic resource: https://dlsanthology.commons.mla.org/text-analysis-data-mining-and-visualizations-in-literary-scholarship/
Pierazzo, E. Diplomatic Reading. Literary and Linguistic Computing, Vol. 26, No. 4, 2011.