Lexos
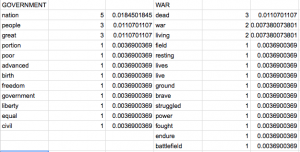
Recently, we have been analyzing the style of our corpora using Lexos and XML. Right now, Lexos is one of my favorite tools that we have used. Style is a very important part of song lyrics and I am glad that I have a better way to look at the style from song to song. As I scrolled through the many tools that Lexos has, I was most interested in the statistics tab. This gives me the amount of distinct terms, average term frequency, along with a few other stats. The amount of distinct terms can tell me about how diverse the language used in American songs compared to the language used in songs from the UK. I took the average of the amount of distant terms from the top 40 in each country and ended up seeing that the UK averages about 100 distinct terms per song while the USA averages 146 distinct terms per song. When it comes to repetition in these songs, the UK average term frequency is 3.8 while the USA’s is 3.3. This shows that the songs that are in the UK’s top 40 use more simple terms and do not repeat as often as those of the USA’s. I did expect for one country to have more simple rhetoric and more repeating, but I sort of expected the USA’s top 40 to have these qualities.
When it comes to comparing the UK and USA top 40s to the Happy and Sad corpora, there are some interesting results. Using the same statistics, we can compare the countries to the mood. The group of happy songs has an average distinct term count of 108 per song. This is closer to the UK top 40, which could be an indication that the UK top 40 has more “happy” lyrics than the USA’s top 40. The happy songs also have an average term count of 3.2 which is closer to the USA’s top 40 amount of average word frequency. This would lead me to believe that the USA’s top 40 is more “happy”. Just as the UK top 40 matches up with the “happy” group of songs in terms of distinct terms and the USA top 40 matches up with the “happy” group of songs in terms of average terms frequency, the UK top 40 matches up with the “sad” group of songs in terms of distinct terms and the USA top 40 matches up with the “sad” group of songs in terms of average term frequency.
These statistics did not actually help me out too much, which is not what I was expecting. I will continue to keep these findings in mind, however, because I think that they could become significant if I have some findings that support them.
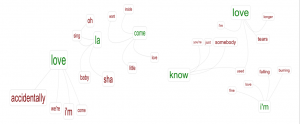
Another interesting tool on Lexos was the dendrograms. Dendrograms are tree diagrams that show relationships between texts based on style.


The dendrogram on the left is the USA top 40 dendrogram and the one on the right is the UK top 40. It looks like the USA top 40 has more songs that have a similar style as opposed to the UK top 40. We can see that there are more songs that have the blue lines in the UK top 40.
XML oXygen
Using oXygen to ‘mark up’ texts has also been a useful way to look at text. When I began marking up a poem by Henry Reed, it made me think of Jigsaw. Jigsaw has a focus on entities and doing markup, we were basically picking out all of the entities.


These screenshots are of my mark up of this poem. It is a good way to simplify the poem and look at what it is talking about. It is then easier to see what is being focused on and what metaphors are being used.
I think that I will continue to explore the tools on Lexos to analyze my text and I do not plan on using XML as much although it is useful. I think that once I can get Jigsaw working as well, I will have a much better time analyzing the sentiments of the songs. This along with style analysis will go a long way in teaching me about my corpus.