My Corpus Construction
I created my corpus using older translations of The Odyssey, The Iliad, The Aeneid, and The Argonautica. I cleaned it manually. The reason why I chose to stick with the old translations of the texts is because it gives me a different view on the text. Because I have read several of these epics I am very familiar with what happens and the trends. One of the things we talked about earlier in the semester was de-familiarizing texts, and I think that using these older translations will properly do that.
Using Voyant and Antconc
The things that I looked at were a word link, a word cloud and a word concordance. The word cloud told me what words were the most important. Using that information I then moved forward to the word link. The word link as seen below:

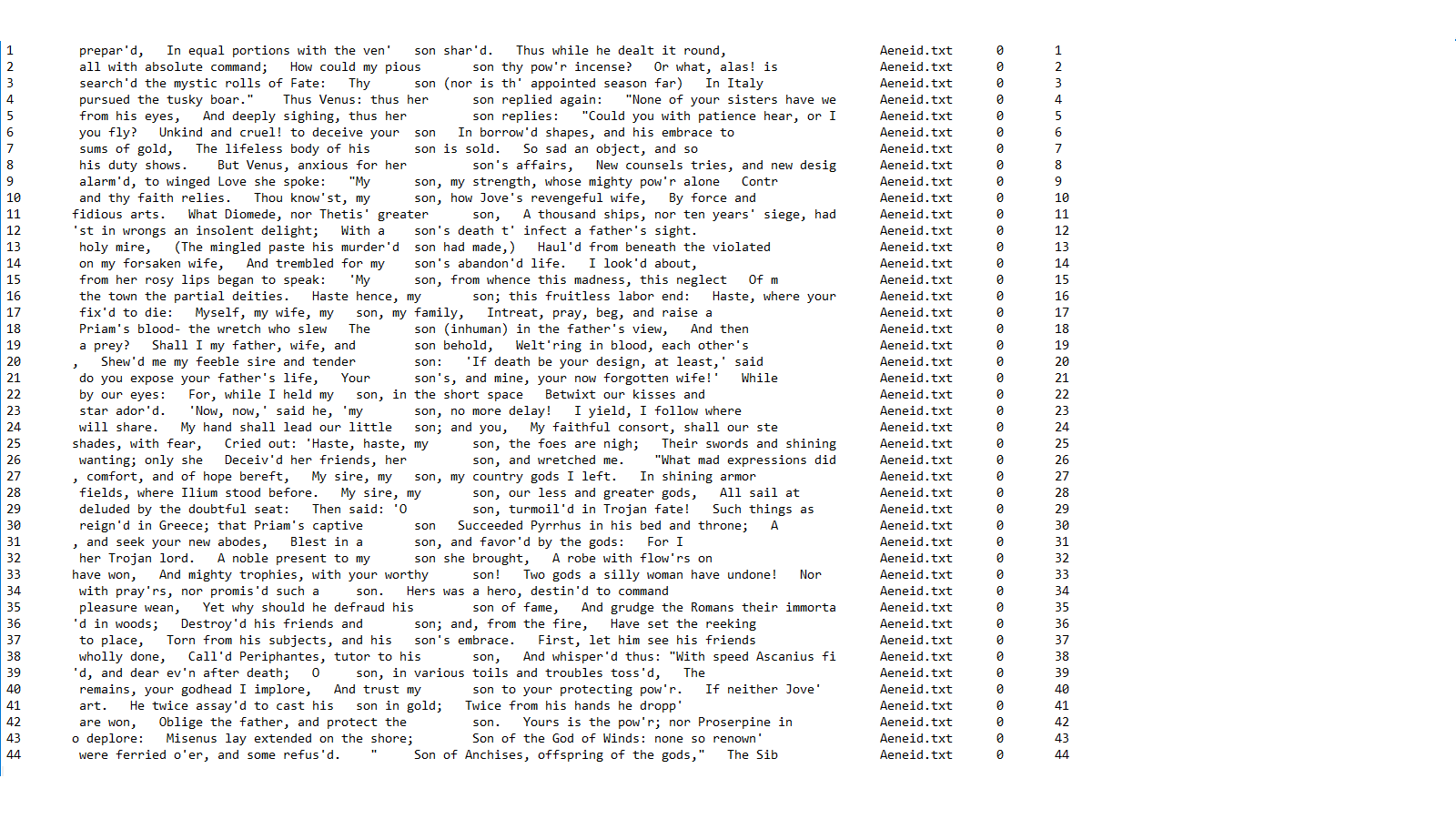
showed me what words were connected. However the connection was out of context. All that was left to do was look at the context using antconc. It gave me the context I needed to properly analyze the text. Seeing what words come before other words allowed me to better see the importance. A word without context means nothing. You only get the true meaning of a word when you see how it is used. Looking at son for example you see that it can be used to inspire different things. Below is the antconc word concordance.
A Brief Comparison
Voyant and Antconc are two different programs, and each is meant to show you a different thing. Voyant gives a more broad overview of the texts using several different tools embedded into the engine. The interface is brighter and easier to navigate. Both of those traits are common of something that is only meant to skim the surface. Antconc is meant to go deeper. It is more specific, and has a more clear purpose. It is meant to show the keyness or the value of a word to a text, and how much it’s used. Voyent shows keyness in a very basic form but antconc is much more adept in showcasing it. Voyent however is very good at showing what words are unique through all of it’s tools, and its mini applications. They are both good programs but they have their specific uses. I am more likely to frequent antconc because of its simplicity.
Pragmatics of my corpus
Studying these programs allowed me to further understand the importance of the word son in epic poetry and the importance of lineage. A huge part of the ancient world is maintaining honor through lineage, and it is interesting to see that carry over into their poetry. You see that very specifically in the Argonautica, where Jason is not even referred to as Jason but as son of Aetes. That might be specific to this translation but even then it still shows the implied translation, and from that you get the importance. Although it happens the most in the Argonautica it happens in all of them and I would have never guessed that it was so instrumental in understanding the epics.