During the past two weeks, in order to investigate text, we’ve tried out different platforms and techniques in which machines read texts. On a macro level, we’ve learned about stylometry and produced dendrograms based on delta and zeta-values in our corpus. On a micro level, we’ve begun to learn XML-compliant TEI markup.
From the lecture last Monday, we learned about stylometry which is used to attribute authorship to anonymous or disputed documents. Besides, stylometry also enables us to think at a comparative and macro level how an author expresses himself or herself. I remembered that during the presentation Dr. James O’Sullivan showed an example of identifying an author’s work among the other author’s works by using dendrograms. Since Lexos provides us with clusters analysis based on delta analysis (based on the most frequent words) and zeta (based on distinctive words), it could identify the differences of a file comparative to another and also show us the relationships across our corpus.
First, I uploaded my screenplay corpus. And for cleaning, I uploaded my own version of stop word list based on what we had from Jigsaw (in the resources folder). I got the result dendrogram in Figure 1.
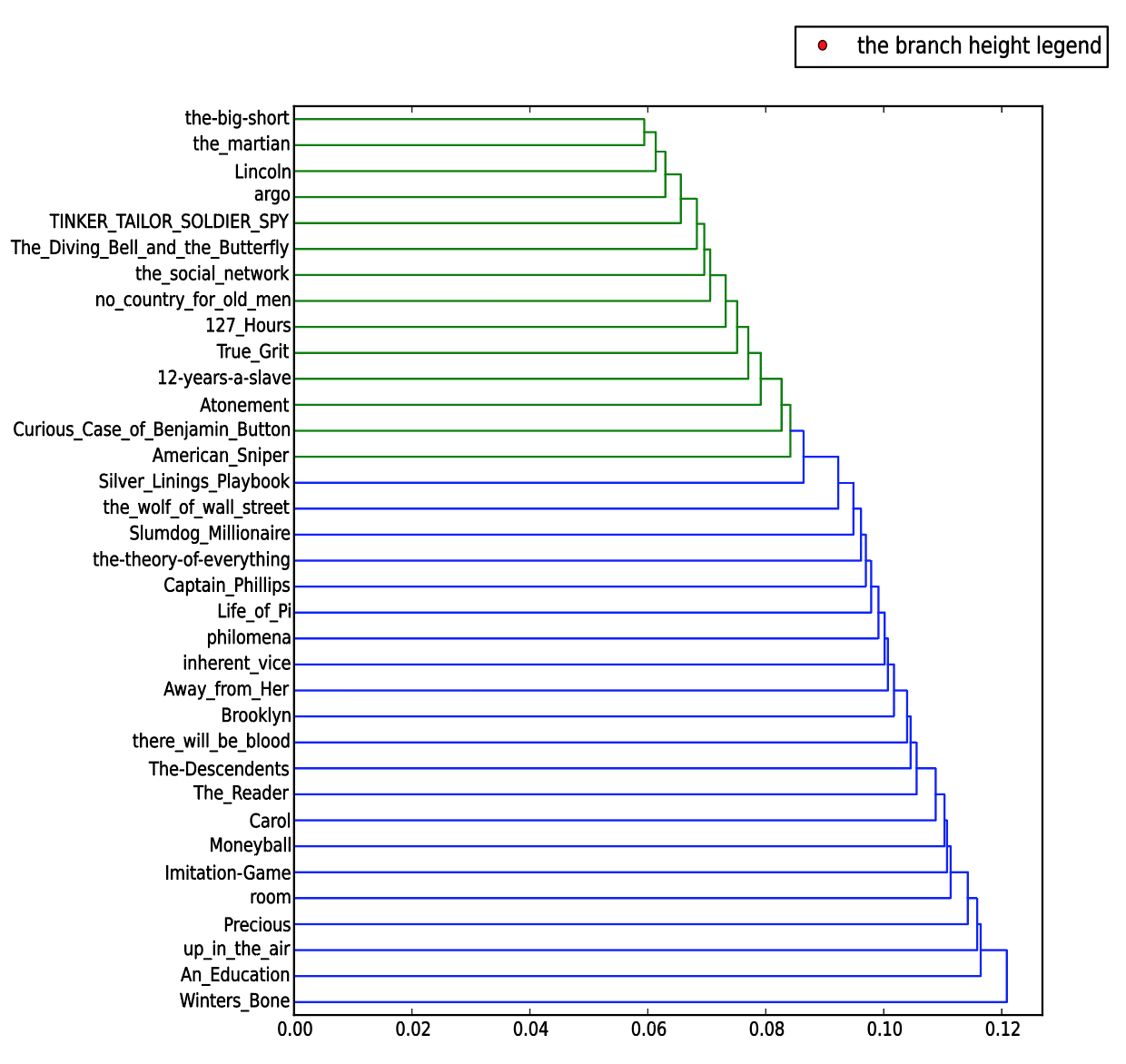
Figure 1: Dendrogram created for screenplay corpus
This graph seems to be interesting but I still did not find why the dendrogram identifies the relationship of these screenplays like this.
In order to understand what the dendrogram means, I thought I could upload my novels corpus to see if there are similarities between these two dendrograms. However, I got another graph that I do not understand. (See Figure 2 below)
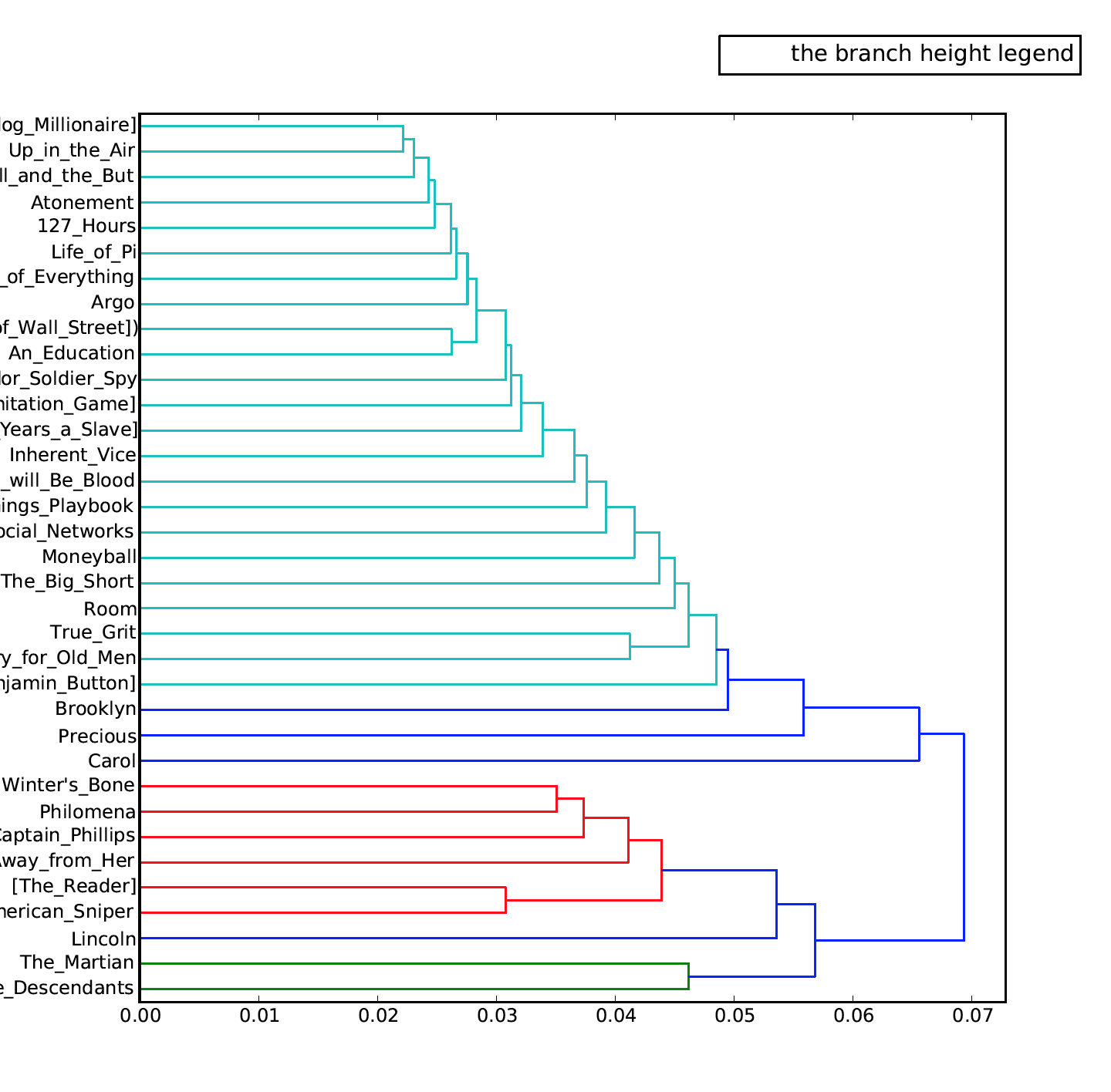
Figure 2: Dendrogram created for novels corpus
I carefully checked the y-axis of these two dendrograms and I did not find any two novels/screenplays are relatively similar (located at relatively closed positions on y-axis) or have similar delta or zeta values. The only finding that I have is that there are only two colors shown on Figure 1 (screenplay dendrogram) and the relationships between screenplays tend to be very simple. However, on Figure 2 (novels dendrogram), there are four colors shown to display the relationships between these novels and the files colored in red are comparatively different than the rest. I think the reason that why these two graphs are different in these ways is that screenplays have relatively more fixed and consistent format than novels. (Screenplays have their own writing formats.)
I believe that there are mainly two reasons that why I did not get interesting results. One is that these screenplays and novels were written by different authors so they have extremely diverse writing styles and diction in their writings and the second is that I do not have a good macro-level understanding of these files. It is still far from enough to only know about the plots of each movie.
During the process of learning text encoding, we first got to know about transcription. According to Pierazzo, the main purpose of transcription is to “reproduce as many as characteristics of the transcribed document as followed by the characters used in modern print.” But there are many features one might want to consider from the infinite set of “facts” that can be found on the written page. Besides, as Pierazzo also states that one of the downsides of the traditional transcription method is that the editors must make judgements on what they need to include and in order to make a consensus across the academia, they need to have rules and guidelines to achieve the best practice. However, it is difficult for scholars to have common guidelines and the transcription process itself involves objective interpretation. That’s when the advantages of using markup language come into play. Following the TEI guidelines, editors could easily keep record of meta-information. We have two separate objects: one is the data model (the source) and the other is the publication (the output). As Pierazzo mentions “one of the reasons why the TEI model effective is because it enables the encoding and transcription of several alternatives for the same segment allowing”, the source file could contain not only a diplomatic edition but also other editions. The advantage of encoding with TEI is that “to all intents and purposes there is no limit to the information one can add to a text—apart, that is, from the limits of the imagination”. And people could really move to the analytic level of the editing process by utilizing XML.
As Pierazzo states that if the editor uses XML (TEI)-based system, “the editor’s goal needs no longer be ‘to reproduce in print as many of the characteristics of the document as he can’ but rather to achieve the scholarly purpose of the edition—a purpose which, by definition, varies.” TEI markup enables scholars to perform different analysis based on their own research purposes. For example, if a researcher is interested in identifying different types of rhymes in poems, he or she could markup the corresponding interesting words; if a researcher is curious about the diction and writing styles that a particular author has when writing novels, he/she could work on markup specific diction and syntax.
As a “researcher” myself, I intend to find the relationships between screenplays and their corresponding novels. XML could really help me markup different entities in the screenplays such as characters, dialogues, scenes, descriptive and background metadata, etc. since a screenplay is a semi-structured textual document.
I marked up a small part of the screenplay of The Theory of Everything based on the hamlet_scene.xml provided.


My next step would be to see how the script writer uses verbs and I will manipulate CSS to make the patterns observable.