My investigation topic is to analyze novels and their corresponding screenplays.
My research questions are:
- What are the differences and connections between novels and their corresponding adapted screenplays?
- What are the differences in pragmatics between novels and the screenplays?
My corpus includes 35 screenplays that were nominated or won Academy Award for Best Adapted Screenplay from 2007 to 2015 and their original novels. I think they are representative because they were selected by many experts and it is guaranteed that they were well-written.
I collected screenplays and novels by searching online. Internet movie script Database (imsdb.com) is a main resource that I found screenplays. After collecting necessary files, I converted PDF files to text file by using a website called zamzar.com and I cleaned HTML files to text file by using an editor called Sublime Text.
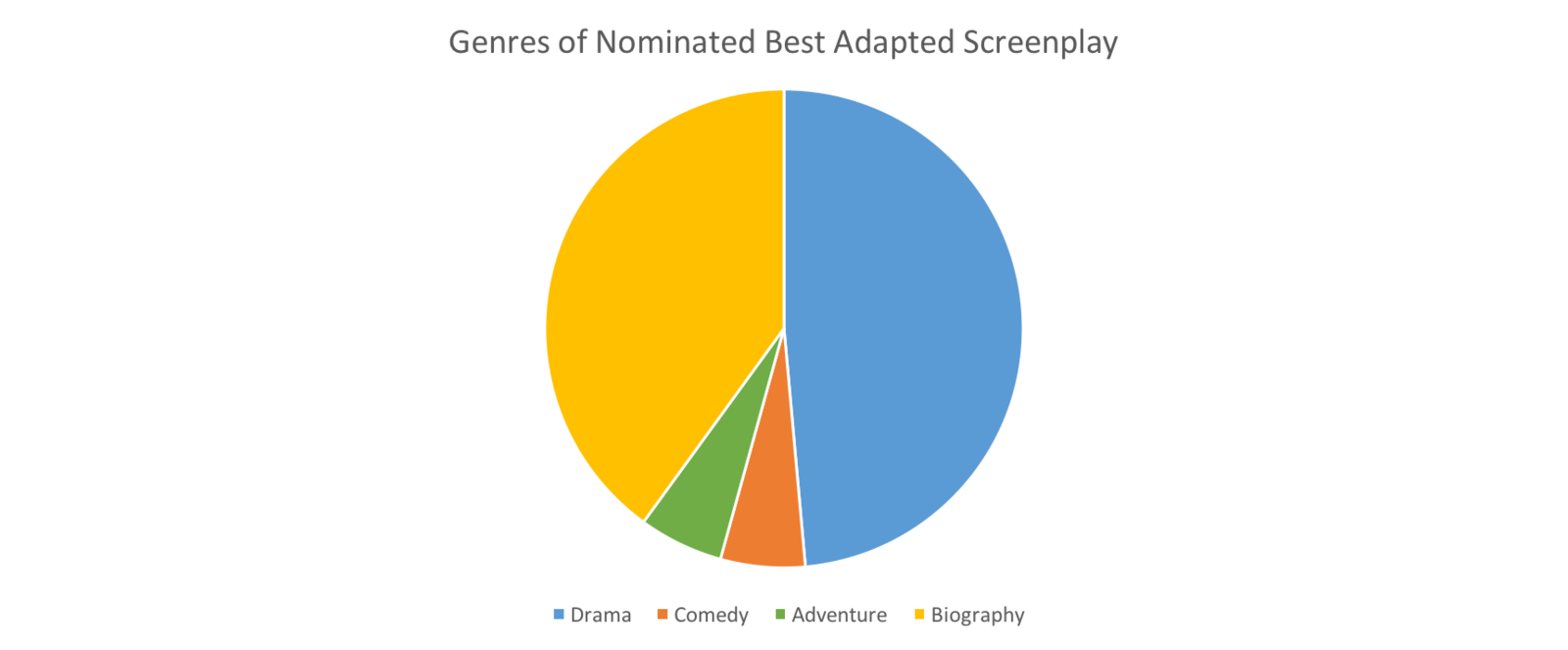
Before I dived into using analysis tools, I found that most of the best adapted screenplay nominations were drama. It is interesting to see that people nowadays like to watch more drama movies. I also think I could look into the differences in pragmatics of screenplays in different genres for future work.
I tried three tools so far including Voyant, Antconc and JigSaw.
I did not get much useful information from Voyant since most of the results were about word frequencies without stop words but in my situation, I need to look in depth about the context of the words in a sentence.


Figure 1 Top five words in novels corpus


Figure 2 Top five words in screenplays corpus
What I could conclude from Voyant is that the word “said” is a good indication about that novels in my corpus were made up by dialogues and the words such as “it’s” and “I’m” are good indications of the colloquialism characteristic of a screenplay. Basically, I think Voyant is a fancy web-based tool with beautiful data visualization. It provides whole and broad pictures of the corpus but it is not very useful for large, various and mixed corpus.
On the contrary, I think Antconc is the most useful tool for me since it provides users the opportunities to really look into the context of the keywords and also to have a comparison between corpus. It is a really good tool for searching keywords (when stop words matter in the process). It provides accurate and useful statistics. Besides, Keyword in context (KWIC) is a good way to start looking for patterns in corpus.
I created a graph with my search results which use men|man|he|his|him|himself|male as representation of words related to male and women|woman|she|her|hers|herself|female as representation of words related to female.
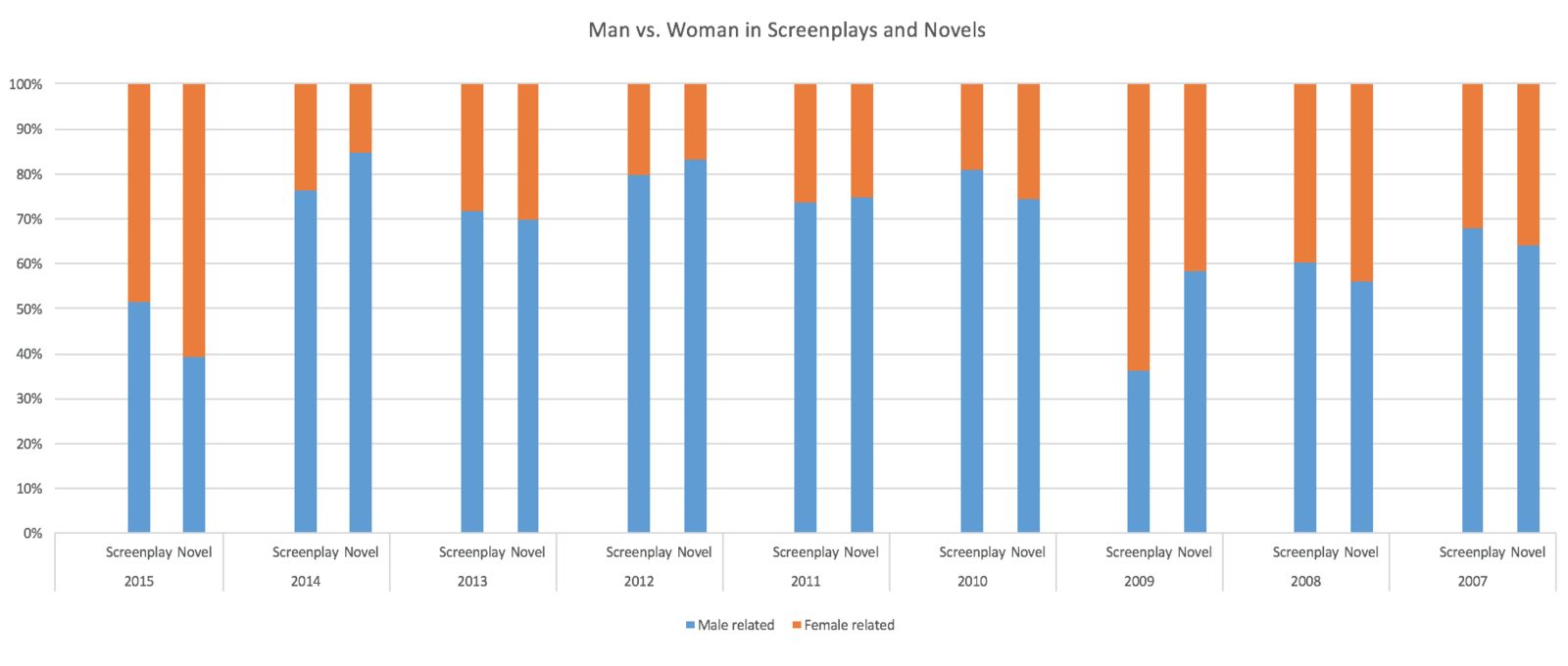
At first I thought there might be a decline in the ratios of men in screenplays/novels, but it turns out that the ratios fluctuates as times go. However, I did get interesting result after I combined the total numbers of searching results that I got from Antconc in the whole corpus.
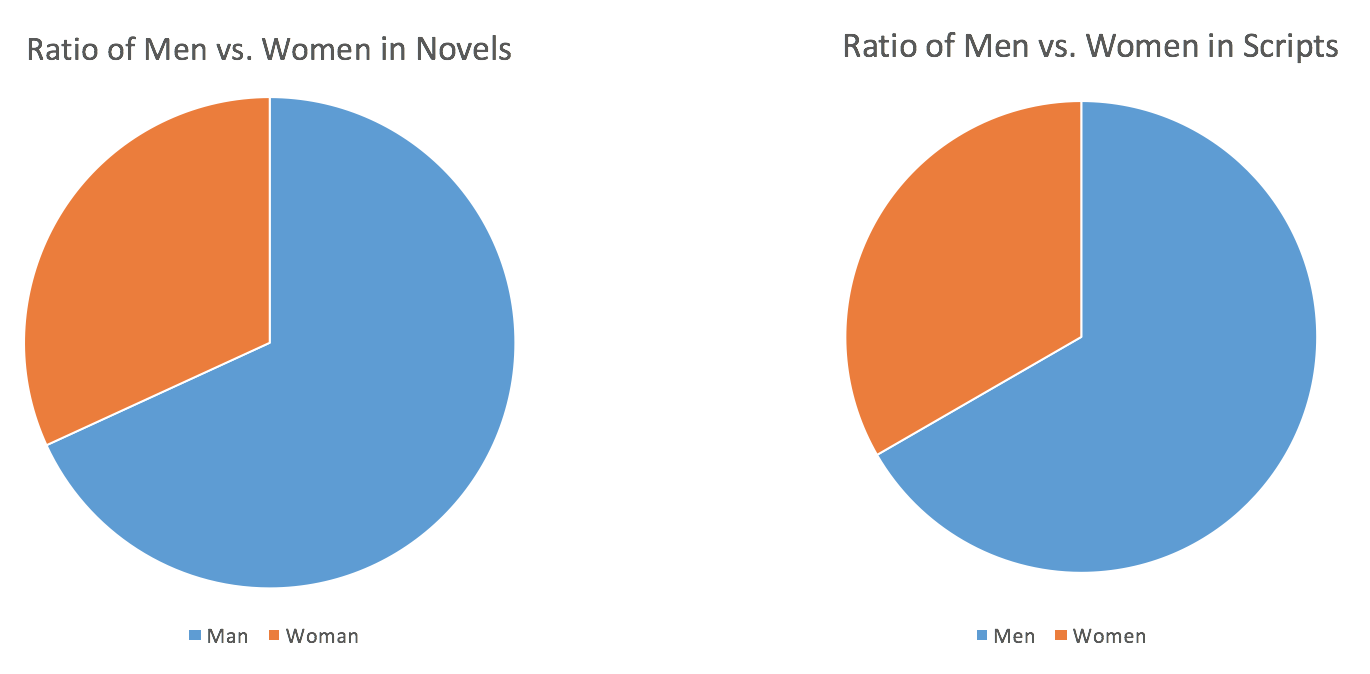
We could see from this graph that the ratios of men in both novels and screenplays are around 66% which is still a large proportion. Besides, it is interesting that the ratios that I got by searching in screenplays and novels did correspond with each other.
Another interesting point that I found using AntConc when I looked into the word list is that in the word list of novels corpus, we saw the word “was” was listed and in the word list of screenplays corpus, the word “is” was listed but not the word “was”.
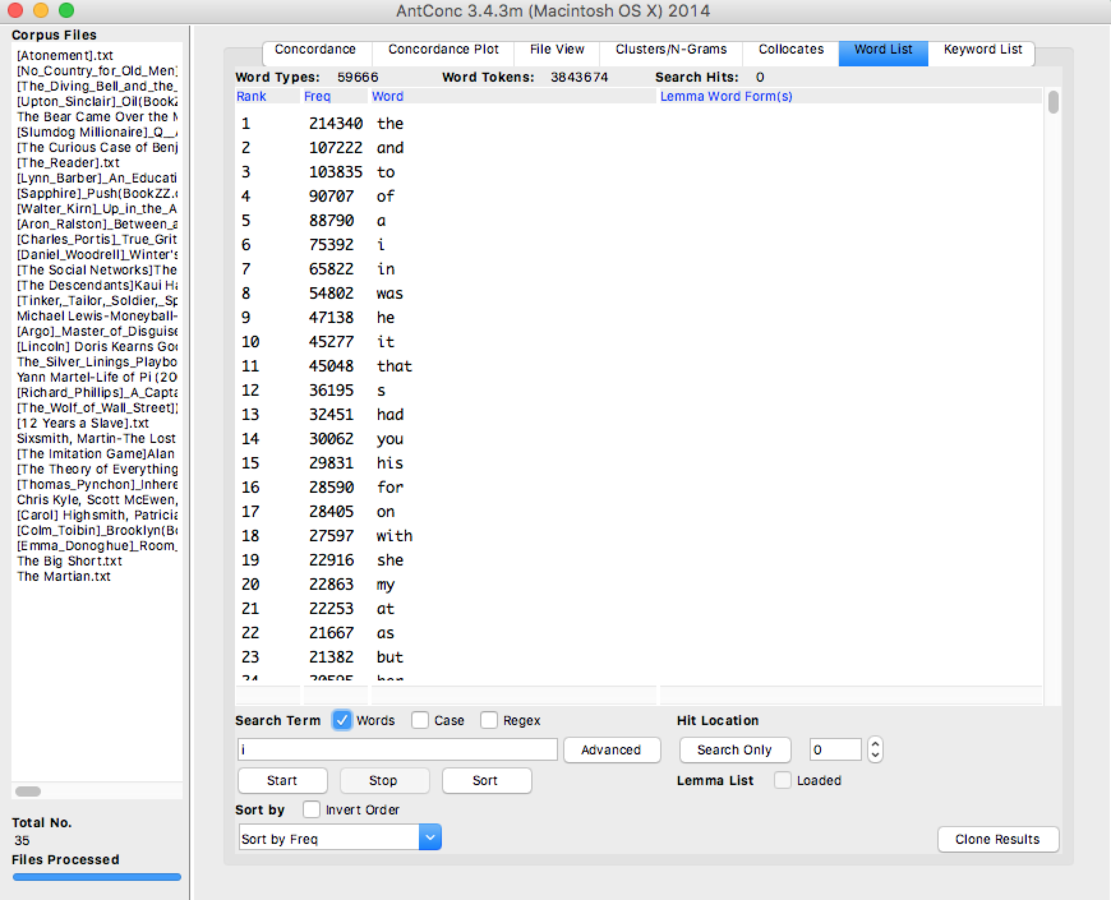
Figure 3 Word list from novels corpus
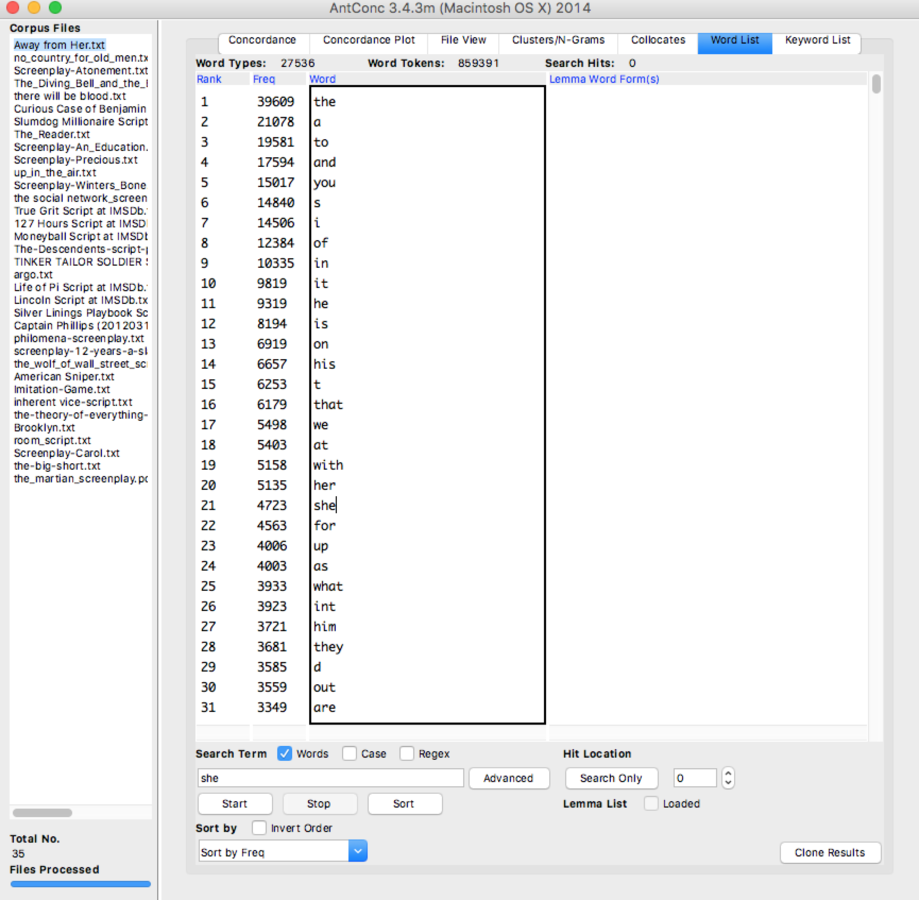
Figure 4 Word list from screenplays corpus
I also got similar results when I used the corpus comparison function of AntConc.
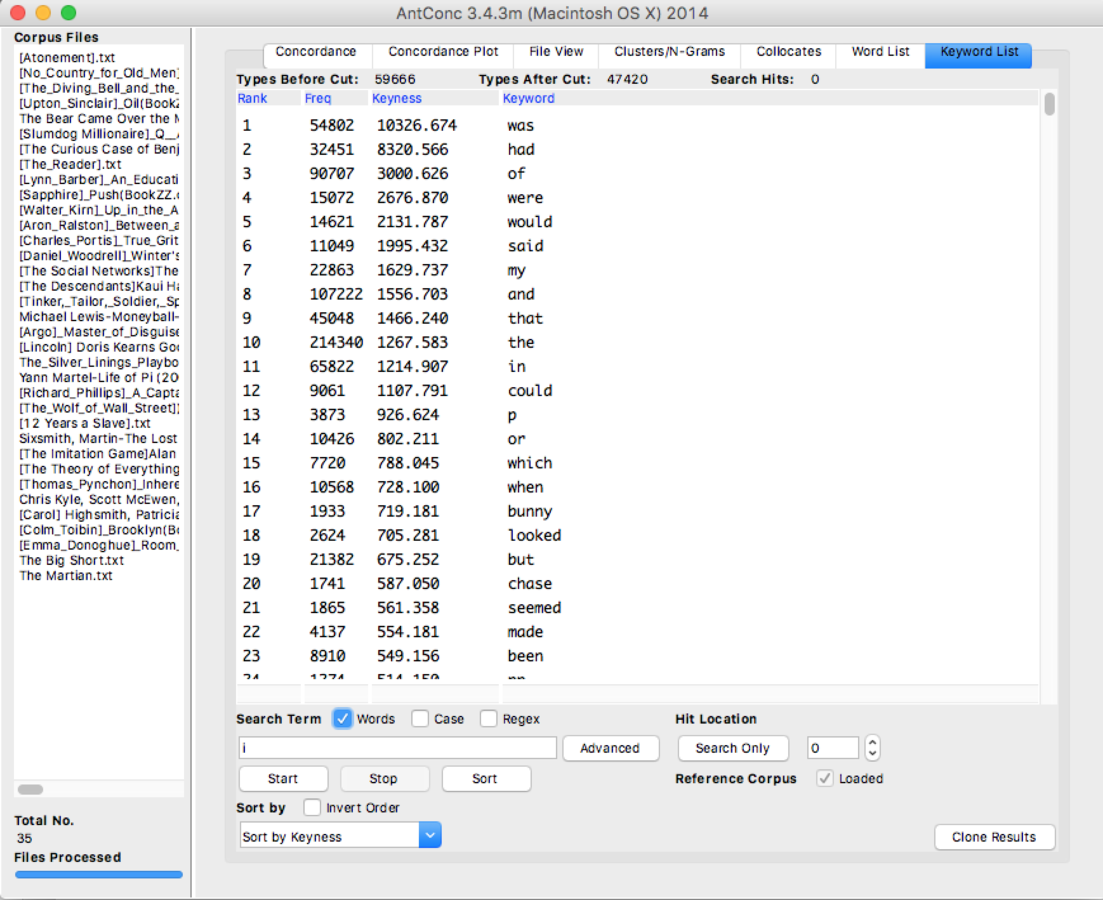
Figure 5 Keyword list from novels corpus
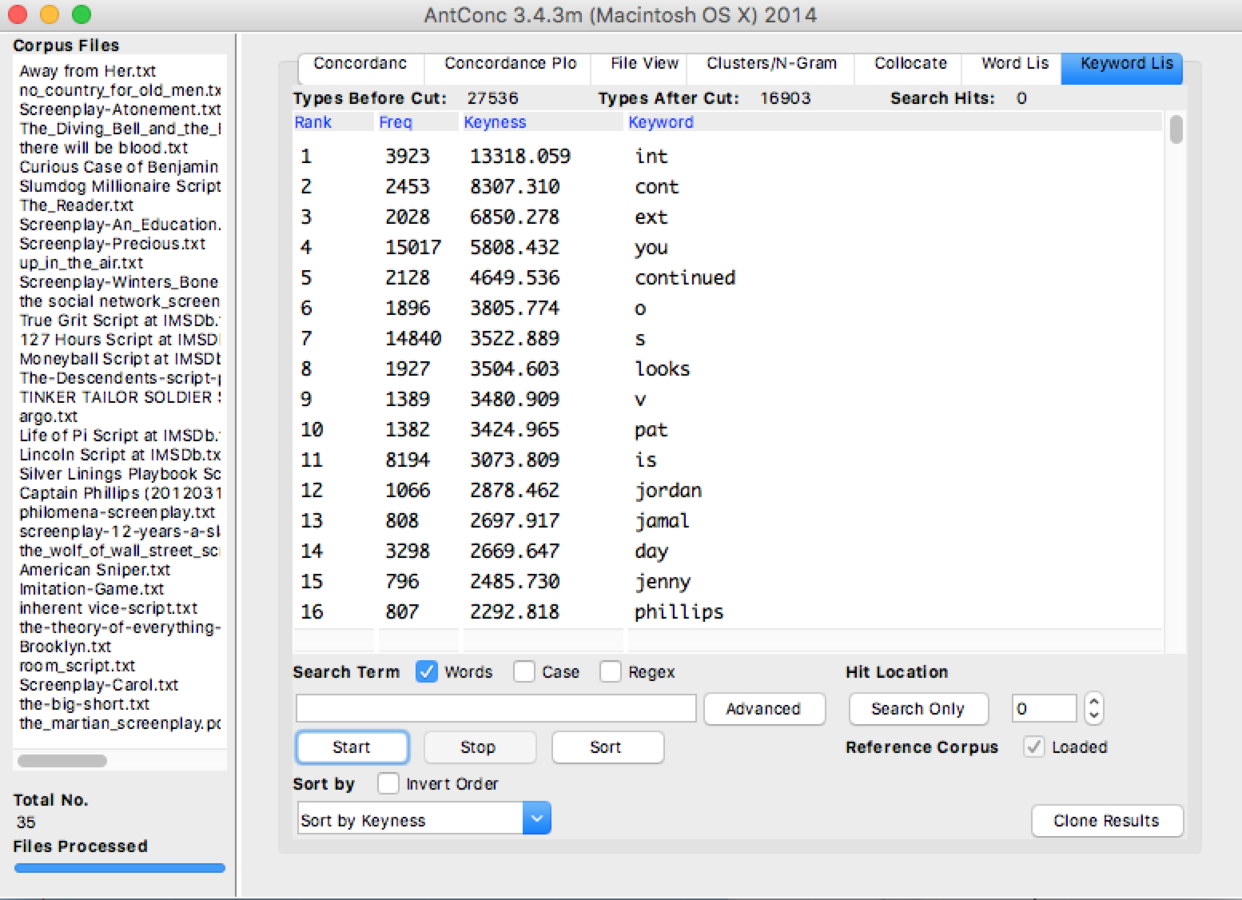
Figure 6 Keyword list from screenplays corpus (int, cont, ext, continued, o, s , etc. were indication words in a screenplay)
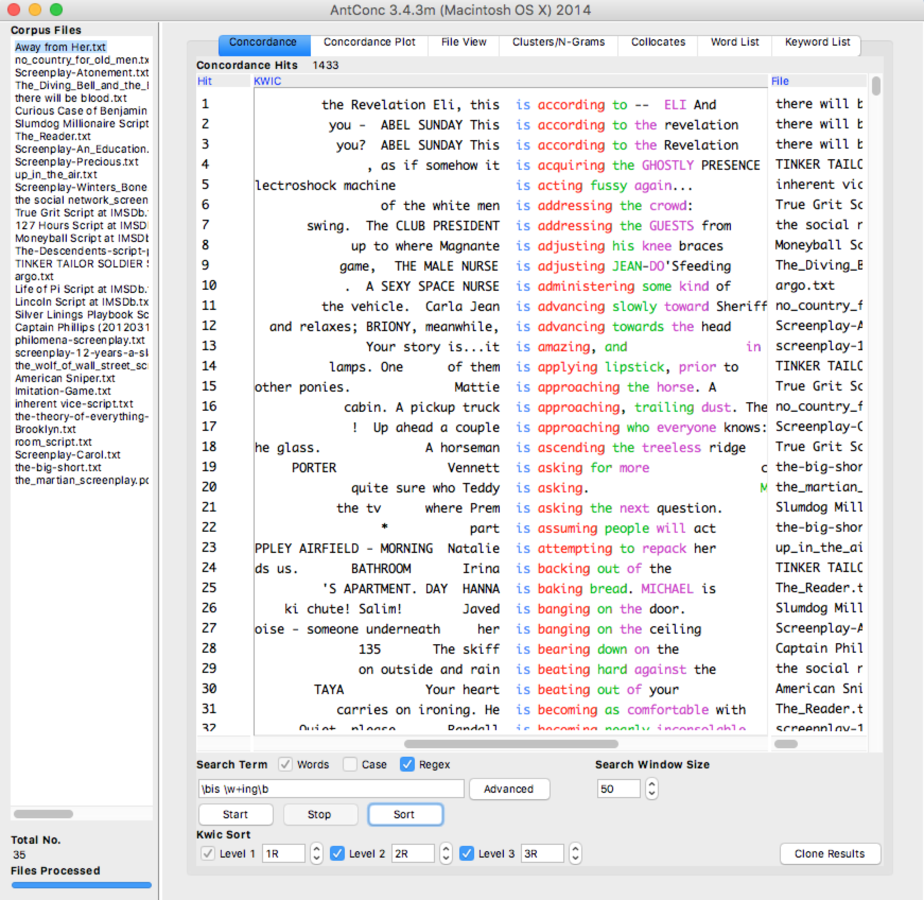
When I looked into the word “is” in the screenplays corpus, I found that there were a lot of present continuous tense. (I searched by using regular expression “\bis \w+ing\b”) It corresponds the nature of a screenplay that it records the on-going events and actions.
For Jigsaw, my problem is that all files in my corpus were longer than 120 pages which all exceed the normal length that Jigsaw could normally analyse. I only tried sentiments analysis on 14 screenplays files and after that no matter how many files I imported into Jigsaw, it stuck and refused to provide sentiments analysis. The result that I got from the 14 files seems to be somewhat useful.
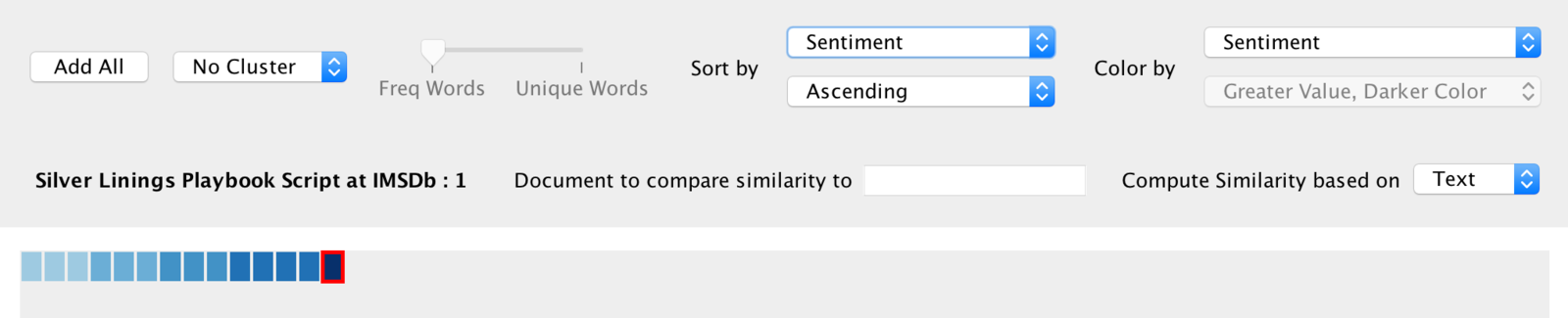
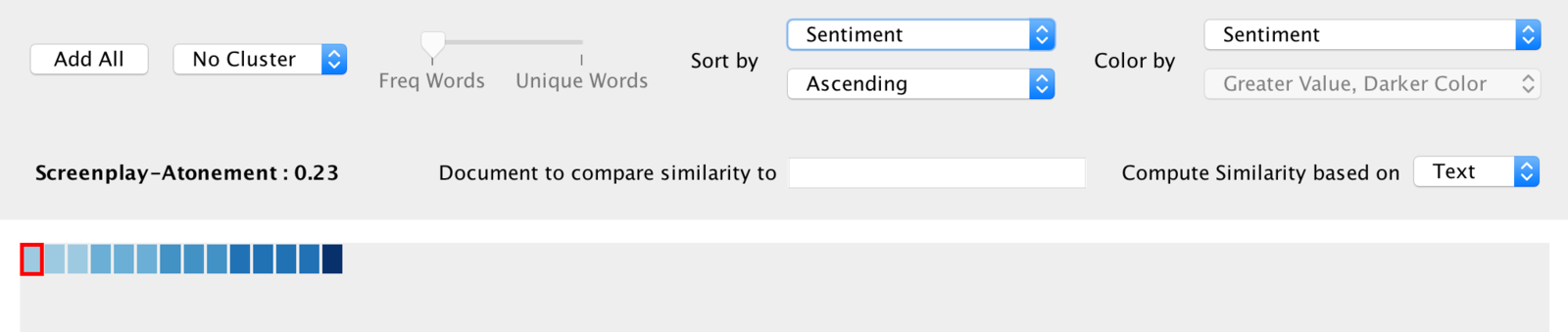
I did saw the two movies (Silver Lining Playbook and Atonement) and I agree with the sentiments results I got since Atonement is indeed a more sad tragedy and on the contrary, Silver Linings Playbook is a happy ending movie. It is also interesting that there is no negative sentiment in the screenplays. I hope the better version of Jigsaw could provide more useful sentiment analysis to my corpus.
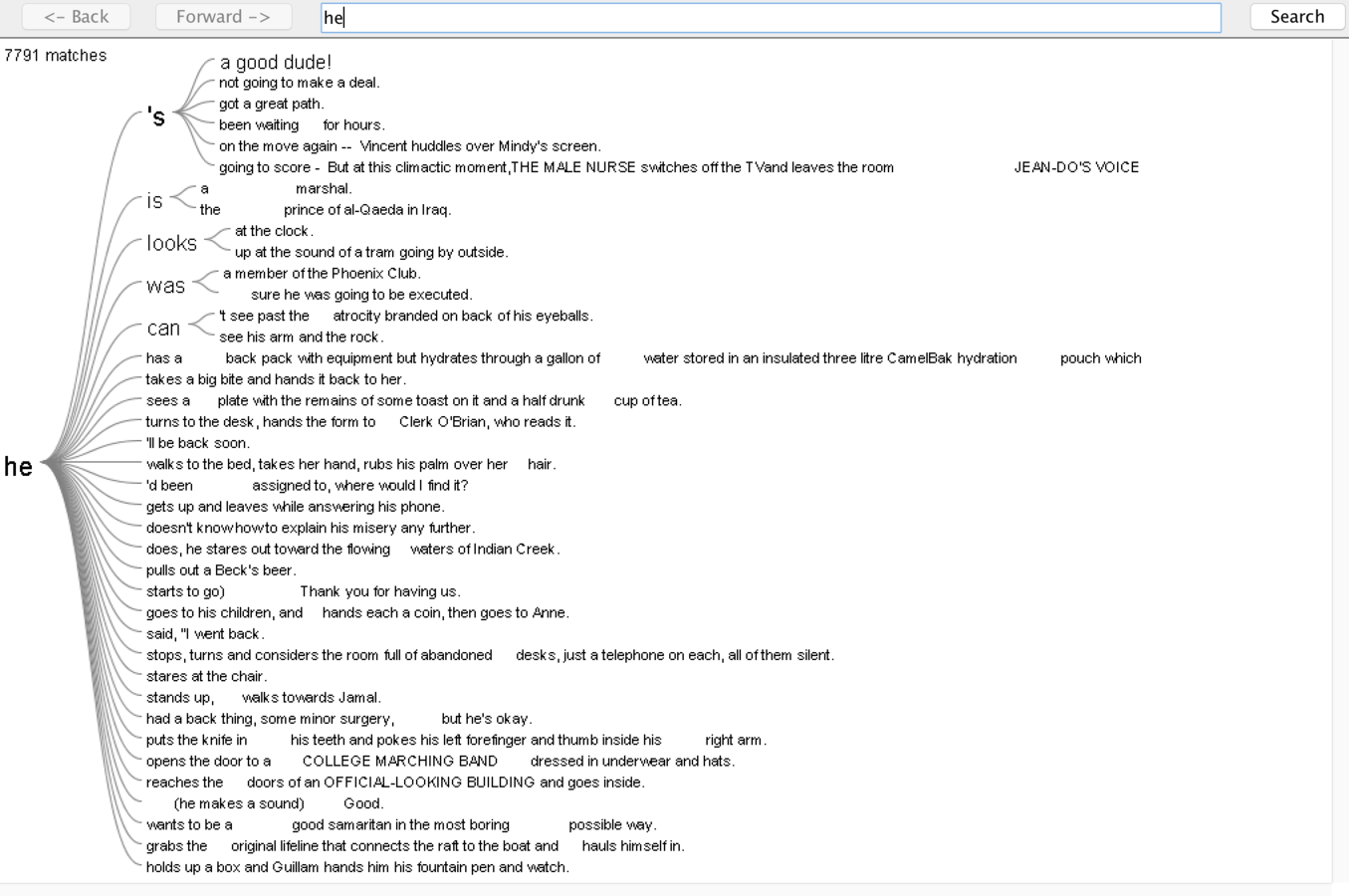

For the word tree I got from Jigsaw, it corresponds what I had from Antconc. But it looks nicer and provides more direct information.
For my future work, I need to
- Apply more linguistic principles to my analyses
- Look into characters
- Take a closer look at the differences in dialogues of characters (what dialogues show about the characters)
- Find out why did directors or screenplay writers choose to make these novels into movies? What are the common characteristics of these novels?
- Find out what is the role that genre plays in the screenplays?
- Use ScripThreads, the software used to analyze screenplays, to see if there would be interesting results when looking into characters