My corpus has not changed much since my las blog post: it is a collection of feminist speeches from Marie Claire. I fount the collection in an article called The 10 Greatest Speeches Of All Time By 10 Inspirational Women:
- Virginia Woolf, ‘A Room of One’s Own’ (1928)
- Emmeline Pankhurst, ‘Freedom or Death’ (1913)
- Elizabeth I, ‘Speech to the Troops at Tilbury’ (1588)
- Hillary Clinton, ‘Women’s Rights are Human Rights’ (1995)
- Sojourner Truth, ‘Ain’t I a Woman’ (1851)
- Nora Ephron, ‘Commencement Address to Wellesley Class of 1996’ (1996)
- Aung San Suu Kyi, Freedom From Fear’ (1990)
- Gloria Steinem, ‘Address to the Women of America’ (1971)
- Julia Gillard, ‘The Misogyny Speech’ (2012)
- Maya Angelou, ‘On the Pulse of Morning” (1993)
Most of the speeches had transcripts available online making my creation pretty simple: copying and pasting them into textedit and making the files plaintext. The only text that was not available was Gloria Steinem’s ‘Address to the Women of America’ a thirty second script I was able to type up myself.
I chose this corpus because of the huge difference in time and location between the speakers. To have feminist speeches dating back to 1588 was a surprise, and I wanted to understand what it was that got these speeches on the list when there are so many other potential speeches in between. I knew beforehand that some of the main words in these speeches would be man/men and woman/women; I guessed, considering the topic, that other top words would be “rights”, and ” feminist”, maybe “vote”. Two of my speeches were actually literary works: a poem and a book so I considered the possibility of that effecting my corpus with different devices and words used for poems than in speeches. The book was also much larger than the rest of the corpus combined and my smallest piece was only a 30 second speech: this would definitely skew my data, something I would have to look for how to deal with once I start my analysis.
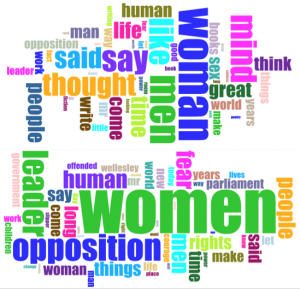
The first thing I did was search the most common words in all 10 texts. I noticed that as I had predicted, my data was greatly skewed, with the most common words in my word cloud only showing high frequencies in the book and not in the rest of the texts. Woman showed in many of the texts but “mind” and “like” were only significant words in A Room of One’s Own. In figure 2 you can see the huge difference that results from removing the book from the corpus: more expected words showed up such as rights and opposition. I think my searches also very much solidified the theory that while computer analysis can be very telling about a text, context is also necessary. I was surprised by “slippers” showing on the wordcloud, unable to imagine a manner in which slippers could be relevant in a feminist speech but when I clicked on it I was taken to a speech addressed to and about “Mr. Slippers”, in which the speaker says his name frequently throughout the text.
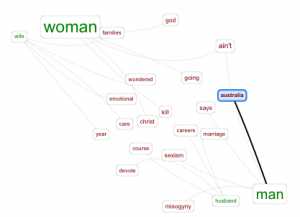

The class’s conversation about words most closely connected to words referring to men and women also sparked an interest in me. I wondered if those same patterns would even be evident in speeches by feminist women. When I did my first search with all ten documents and did come up with the words “families”, “children”, “emotional”, and scarily, “beating”. For the nine shorter documents I got “families” and “children” again as well as another violent word, “killing”.
I used the collocates tool a lot more on antconc than I did for voyant. I think in Voyant I was distracted by the image producing tools: I spent sometime trying to figure how to make the “knots” tool at all relevant to my research. Collocate from Antconc is important in giving context to those visual representations. Some important terms I saw were “man predominates” and “men guffawed” terms that give a certain visual versus “women should” “women cannot” and “women forced”. These observations represent to me the belief in the speaker’s of a powerful man overpowering or lording over trapped women.
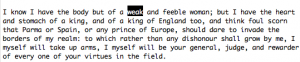
Another interesting find from my search was the “feminism-levels” of women based on the time period. The earliest speech, Elizabeth I’s speech to the Troops, shown in figure 5, shows that she is aware of the men’s view and opinions of her but does not seem to see an issue with it. Instead of speaking of women as equals to men she speaks as if she is an exception in her likeliness to a man. Its not “I am strong because women can be strong” but rather “I am strong because I have a man’s heart”.
While voyant was nice to use as a way to begin analyzing the corpus I it was easy to distracted by the visuals it provided. Antconc, although a little boring in its visual representation allows a researcher to focus on the key terms and patterns uncovered by Voyant and more deeply analyze them. Antconc to me seemed to dive more into the text, going back to find the context of what certain results mean and to confirm assumptions made from the visuals of Voyant. Both look at unique words and vocabulary but the way they represent them is very different even though some tools are similar.
The process has definitely helped me find some interesting insight to the texts, showing me patterns that were completely unexpected as well as confirming results I had predicted. My main goal had been to find similarities and patterns of what makes a great feminist speech but the differences between the texts in the corpus make it difficult to analyze that well; however, despite fears of skewing I was able to find data and the beginnings of a pattern in my text.
My pictures are acting up heres a link to the presentation: https://docs.google.com/a/bucknell.edu/presentation/d/1EnOfkOXKJg8R43H3nE3OP6nDSA0d7pyB6wzHodHvwwo/edit?usp=sharing