- About my corpus construction
So far I have 35 screenplays and their corresponding novels/stories ranging from 2007 to 2015. It was a long journey to collect these 70 documents. I searched throughout the Internet and used various tools including Sublime Text and file converters to eventually get them all into valid text format.
After I got used to this process, I think it would be easier for me to enlarge my corpus size and I will continue to increase my corpus collection.
- My differential analyses
Since technically, I have two separate corpora, one for screenplay and the other one for original novels, I think I could have three possible cross-comparisons. One is a comparison among all screenplay scripts, one is among all original novels and another one is a original novel with its corresponding screenplay. The last one would be the main focus of my exploration but the other two comparisons are easier to achieve so I tried them at first.
Beside common character names, I also typed in stop words such as cont’d, int, continued, V.O.(voice over), ext which are common transition words in a screenplay.
Voyant became extremely slow after I loaded my 20 files corpus and it became extremely slow when I tried to type in stop words. But eventually, it did provide me with some results. In the corpus of screenplays, most frequent words are it’s (1,591), i’m (1,482), mark (1,426), pat (1,345), room (1,280).
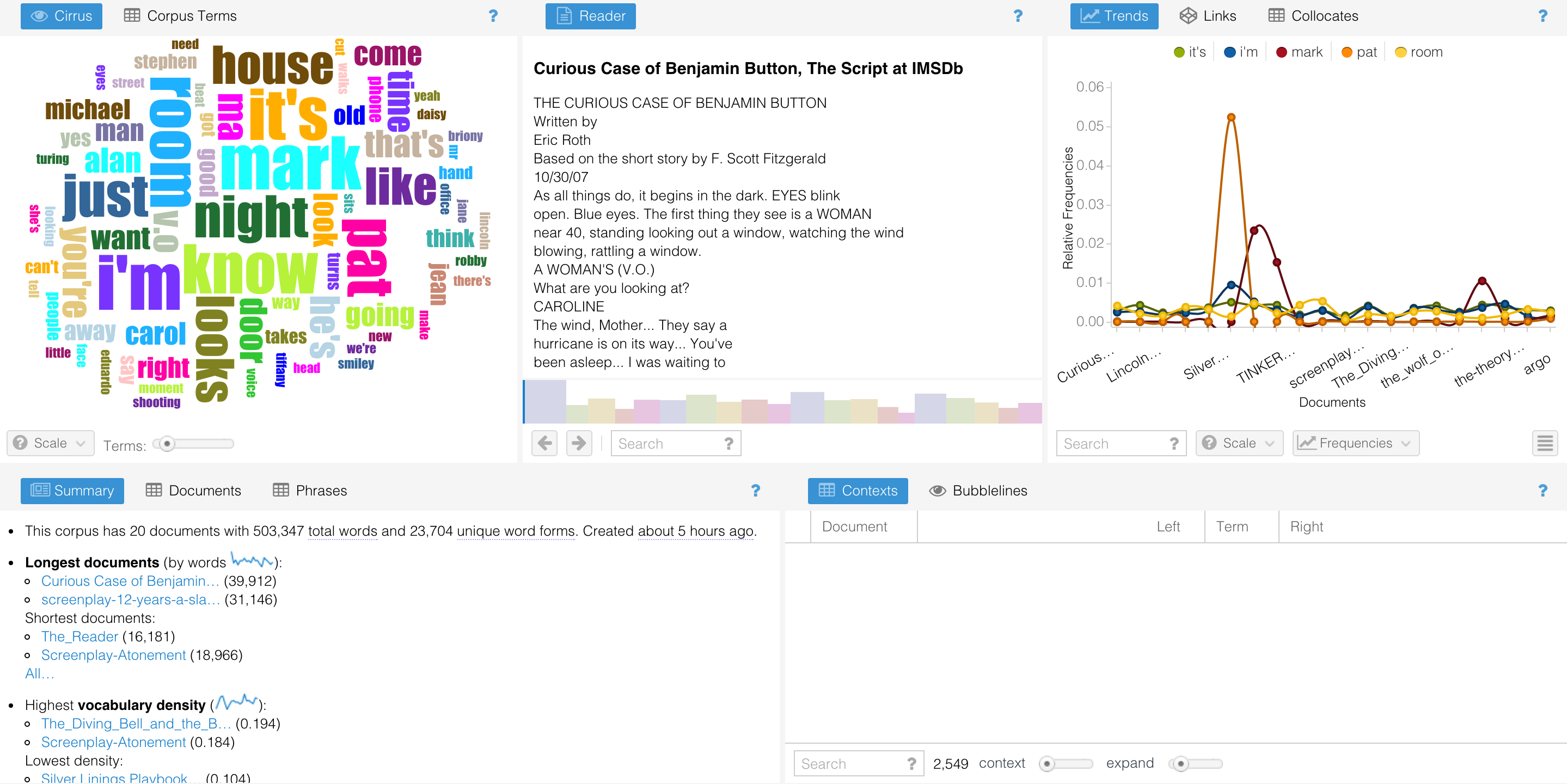
In the corpus of novels, “said”, “like”, “just”, “time” and “know” are the top five occurrences words. (Most frequent words in the corpus: said (6,854), like (5,365), just (4,528), time (4,521), know (3,638).)
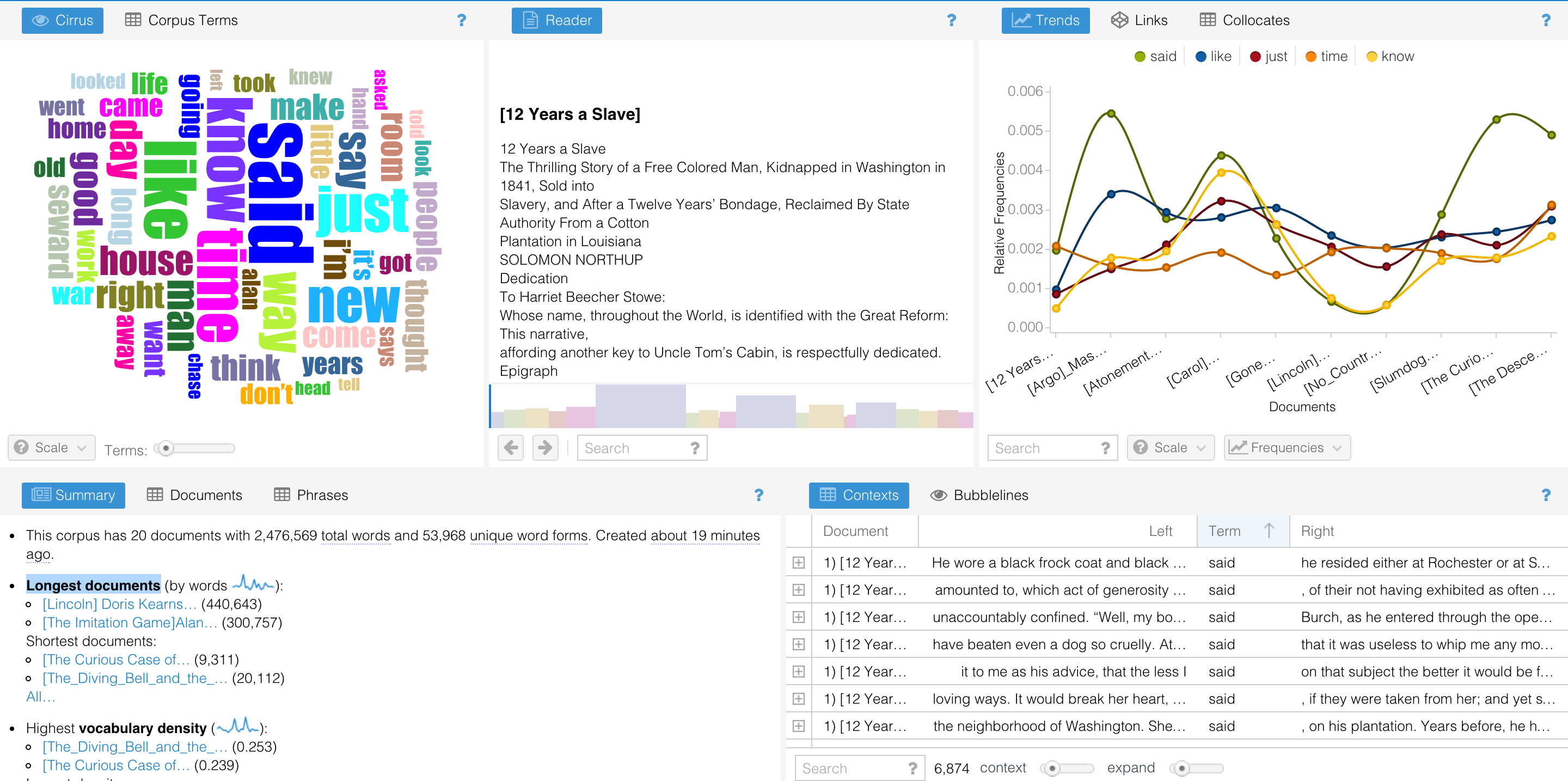
I could also look at the trends of each top five occurrence word among the whole corpus of novels.
Additionally, Distinctive words (compared to the rest of the corpus) are also displayed by the website:
- [12 Years a Slave]: epps (179), northup (128), bayou (124), tibeats (77), burch (62).
- [Argo]_Master_of_Disguise…: mcconnell (174), mendezwith (172), disguise (325), antonio (177), malcolm (174).
- [Atonement]: briony (394), cecilia (220), robbie (152), lola (145), tallis (79).
- [Carol] Highsmith, Patric: therese (1,354), carol (1,302), abby (191), carol’s (189), harge (97).
- [Gone Girl]: amy (870), nick (671), dunne (212), boney (189), desi (146).
This will give me a better understanding of each individual novel.
I also looked at gender marker throughout the corpus of scripts.
This is the result after I kept gender marker for my corpus of novels.
The occurrence of words of male is still larger than that of female. (Although some films are mainly about the story of a man, I still think it is worth analyzing). I also think it would be interesting to compare the ratio changes (the occurrence of words of male to that of female) between present work and older work in order to see if the awareness of gender equality increases gradually.
- My analytical searches in Voyant and Antconc
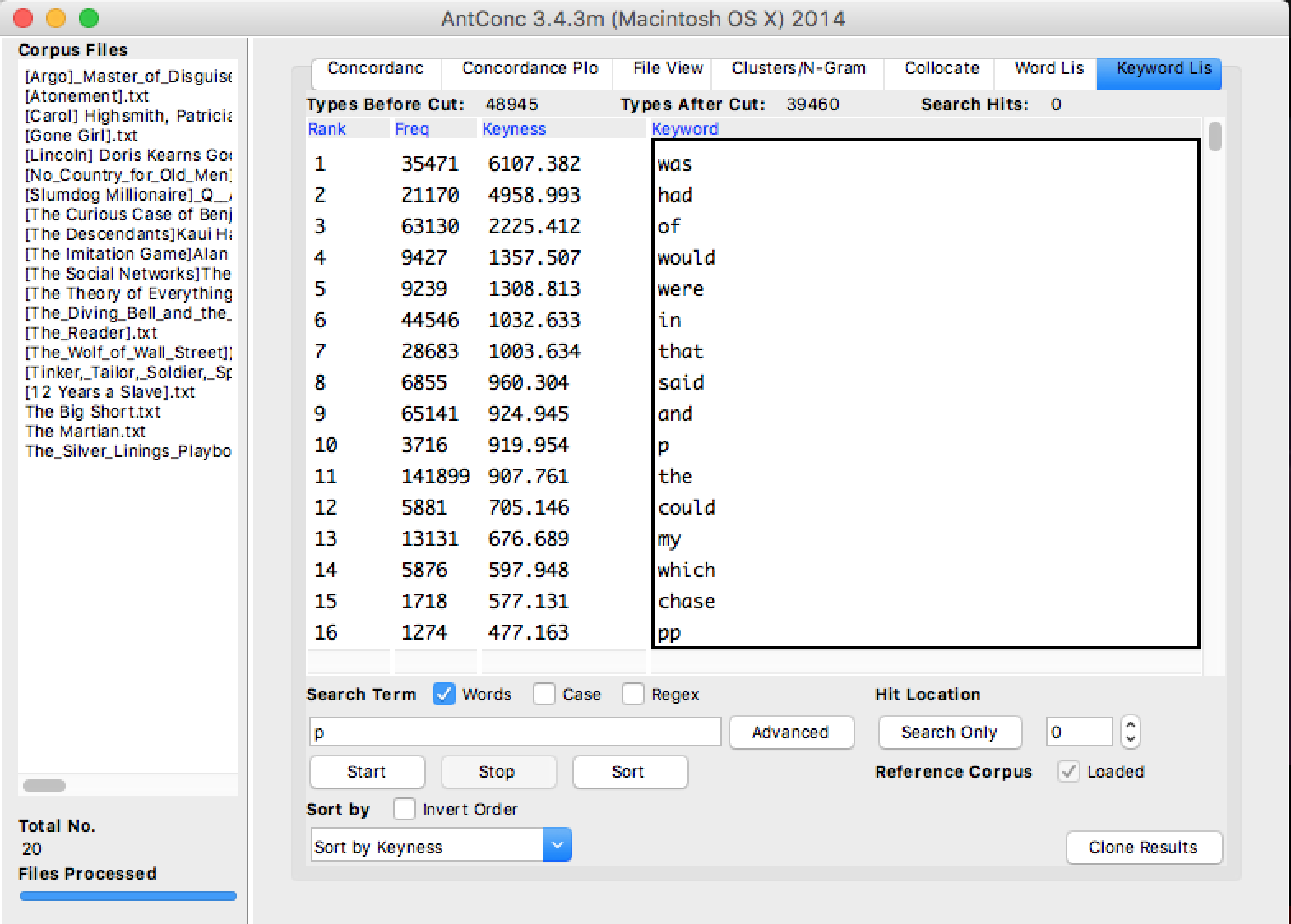
For analytical search in Antconc, I used the keywords list tool which enables us to find words that are unusually frequent in the corpus when compared to the same words in the reference corpus. The measurement of unusualness is called keyness strength. The words with significantly different frequencies from those in the reference corpus is called keywords. So in my exploration, I chose corpus files to be the corpus of novels and the reference corpus to be their corresponding screenplay. We could see that “was”, “had”, “of”, “would”, etc. are some of the keywords from the novel corpus. I’ve tried to swap these two corpus but the results of screenplay as corpus files are mostly about common transition words in screenplay such as: int, ext, continued which are not very useful since Antconc do not allow us to type in stop words.
Another interesting finding that I found thanks to Longest documents (by words ) functionality of Voyant is that the screenplay of Curious Case of Benjamin Button has 39,912 words which is the longest among the 20 screenplays that I collected. However, it was adapted from the short story by F. Scott Fitzgerald which has the shortest length of all 20 novels/stories that I collected. I will have an in-depth look at this unusual case.
- A comparison between the platforms
As for the comparison between the platforms, Voyant and Antconc are similar in some extent but also different in their own ways.
We could see that both Voyant and Antconc have the functionalities of analyzing word frequencies of the corpus and they both allow the users to look at the contexts of the searched keywords. They both provide a whole picture of the corpus analyzed. Voyant is a great visual tool since it provides various types of graphs including bubblelines, trends, links, collocates,etc. It also provides information such as highest/lowest vocabulary density, longest/shortest documents, frequent words and distinctive words among the corpus. Although I agree these functionalities are cool and fancy, I still doubt that it could give us real analysis about a corpus. It mainly provides us with very broad views and analysis of our corpus.
On the other hand, Antconc provides both broad(macro) and detailed(micro) information about a text. It also allows the comparison between two corpora which is something we could not do in Voyant. We could easily swap these two corpora to get new results, as I’ve shown in my analytical analysis part above. I personally like Antconc more since it allows the users to really analyze the contexts and look at the details of a corpus. It provides sort function that I think is very useful to look at for a particular type of work, such as poems and speeches. However, no tool is perfect. The user interface of Antconc is not good and sometimes it loads slowly or just simply freezes.
- What extent has this process of corpus construction and analysis revealed insights into the pragmatics of my corpus?
From my exploration that I had with Voyant and Antconc so far, I find that they only provide superficial analysis of a corpus; but for my work to analyze the differences and connections between novels and their corresponding screenplays, I think I need in depth and focused analysis. As Anthony, the creator of Antconc states in the article “A critical look at software tools in corpus linguistics”, “if a corpus linguist can develop their own tools they can then do analyses not possible with concordancers, do analyses more quickly and more accurately, tailor the output to fit their own research needs, and analyze a corpus of any size.” So as a computer science major student, I think it is definitely useful and critical for me to create my own way to analyze my corpora. I’ve decided to use Python to extract dialogues from the screenplay and compare them with those in the original movies and I will also use other tools to support my analysis. I think the use of diverse tools would definitely help me get more insights into the corpus.
==========================================================
Modified part starts here:
When I looked back this blog, I did realize some inappropriate methods that I used when I tried to analyze the corpus. In order to combine close reading and distant reading, I feel that I need to zoom in and just focus on some of the small amount of files.
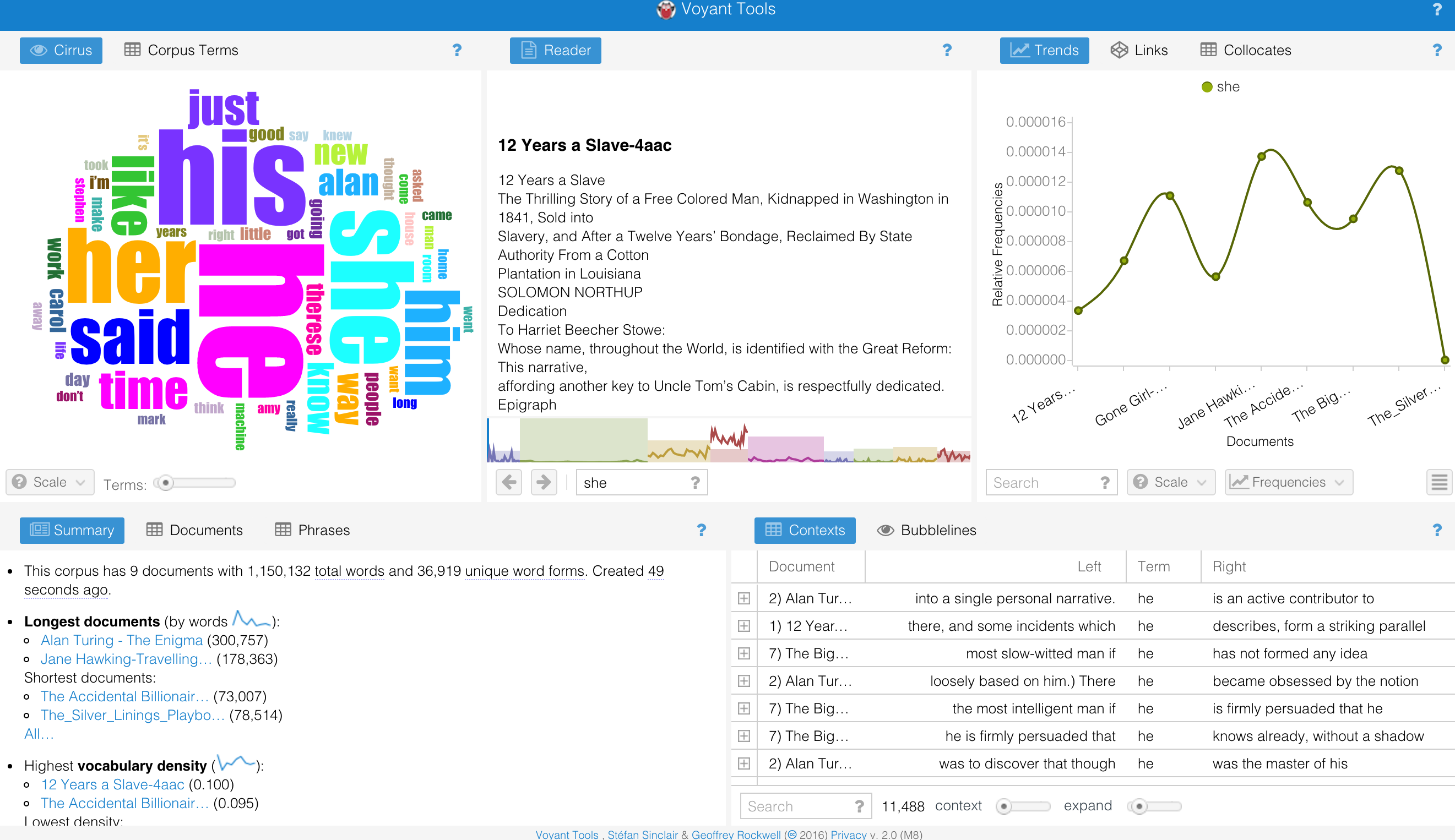
This time I focus on the dialogues from the 9 winners of Oscar Best Adapted Screenplays. I did find some interesting results.
This is the word cloud that I got from uploading all the dialogues in these movies. The word “know” is the most frequent among these dialogues. Similar things happened when I uploaded each individual file. This at first does not make me feel very odd since “know” is the 8th most common word in English according to Oxford English Dictionary.
I decided to remove all the stop words provided by Voyant in order to learn more about verbs or pronouns. Then I found very interesting results below.
I got the most frequent words in the corpus are you (3,176), the (2,892), to (2,245), i (2,144), a (1,943).
After reading parts of the “The Secret Life of Pronouns”, I had a better understanding of different words in the language use. Some conclusions that the author gets are “Men use articles (a, an, the) more than do women” and “Women use first-person singular pronouns, or I-words, more than men”. Then I looked into the screenwriters of all these screenplays. Saddly, all the screenwriters are male. But it is a little contradictory with the results that the author mentioned in the book since from the Distinctive Words section, we could clearly see that “I”, “im” and “im” are distinctive words for movie Precious and The Descendants. Their screenwriters are all male but why they used so many “I” or “I’m”. Everything suddenly made sense when I looked into the authors of the original novels of these two movies. THEY ARE ALL FEMALE! It is very interesting. It either means that these two screenwriters write like women (there are some examples of male screenwriters write like women in the book) or perhaps they tend to keep the pronouns of the original authors of the book.
Distinctive words (compared to the rest of the corpus):
- Imitation-game-movie: enigma (30), alan (55), turing (30), machine (28), german (19).
- 12-years-a-slave: roll (75), platt (50), master (54), nigger (49), jordan (46).
- argo_dialog: foreign (49), iran (32), language (46), tony (27), farsi (25).
- big_short_dialog: bonds (50), mortgage (49), swaps (33), housing (30), eh (36).
- descendantsthe_dialog: scottie (34), matt (30), dont (36), im (48), youre (23).
- nocountryforoldmen_dialog: yessir (17), llewelyn (14), sheriff (20), goin (17), ain’t (30).
- precious_dialog: l (344), l’m (77), ms (47), precious (58), ng (26).
- slumdogmillionaire_dialog: jamal (65), salim (22), rupees (21), hindi (20), malik (18).
- social_dialog: dont (82), facebook (49), harvard (42), eduardo (32), thats (41).
Then I loaded in all the original novels. It is surprising that I got similar results.
Distinctive words (compared to the rest of the corpus):
- [12 Years a Slave]: epps (179), northup (128), bayou (124), tibeats (77), solomon (77).
- [Slumdog Millionaire]: salim (211), rupees (131), kumar (108), prem (103), neelima (84).
- [The Imitation Game]: alan (1,706), turing (714), mathematics (300), alan’s (264), manchester(174).
- Argo: mcconnell (174), mendezwith (172), disguise (325), soviet (212), cia (211).
- No Country for Old Men: dont (447), didnt (200), aint (200), chigurh (118), yessir (90).
- The Big Short: subprime (505), eisman (327), loans (274), bonds (361), burry (176).
- The Descendants: scottie (533), sid (240), joanie (220), i’m (429), alex (423).
- The Social Networks: eduardo (527), sean (211), tyler (204), facebook (141), he’d (329).
- Precious: ms (147), miz (92), i’m (343), git (67), wif (65).
Then, I also used AntConc to check my results and it showed similar results as Voyant. So I guess it’s because these two screenwriters did tend to keep the pronouns of the original authors of the book.
These findings give me new understanding of using Voyant and AntConc. And sometimes stop words are as important as other words since they might also show important results.